I gave this talk last week at the vLLM Meetup and KCD (Kubernetes Community Days): lessons from building Nowledge Mem. Not a product pitch. The actual engineering problems we hit, and how we think about them.
The talk is in Chinese. The video recording is on Bilibili: 《为 AI Agent 构建记忆系统》. This post is the deeper, English version of the same material.
This post goes deeper than the slides. If you were at the talk, treat it as extended notes. If you weren’t, it stands on its own.
The problem
You spend two hours in Claude Code making an architecture decision. Next day you open Cursor. It knows nothing about that decision.
This is AI memory in 2026. Every tool builds its own: ChatGPT stores key-value pairs, Claude uses a file system, Cursor uses glob rules. None of them talk to each other. The average power user touches 4 or 5 AI tools daily. Each one assumes it’s the only one.
The question is not whether AI agents need memory. It’s what kind, and how to build it without ending up with a junk drawer.
Three paradigms
When people say “memory for AI,” they mean different things.
Parametric memory bakes knowledge into model weights. KBLaM (Microsoft, 2025) and MSA (EverMind, 2026) take this approach through fine-tuning and weight-level integration. It’s a model-layer concern.
Agent memory gives agents cross-session persistence. Most of the energy has gone here, the challenges we’ll discuss mostly originate here.
Memory as product is the layer we work at. It inherits every agent memory challenge and adds more: cross-tool continuity, temporal reasoning, knowledge evolution, and the experience of trusting an AI system with your knowledge.
How the field got here
The field has gone through four phases in three years:
- Cognitive simulation (2023). Generative Agents introduced memory streams with reflection. Voyager stored executable code as skills. First serious attempts at memory consolidation.
- OS metaphors (2023–25). MemGPT had the cleanest framing: context as RAM, LLM as CPU. MemOS extended it to schedulable memory resources.
- Data infrastructure (2024–25). It’s proved this was not just an academic problem. Zep built temporal knowledge graphs. AWS AgentCore commoditized the basics.
- Learnable memory (2025–26). A-MEM self-organizes indices (Zettelkasten-style). MemSkill uses PPO to learn operation strategies. MemEvolve evolves the architecture itself.
The direction is consistent: decision authority over memory structure and evolution keeps shifting from humans to agents. The shared assumption across all four phases is that memory serves the agent.
What cognitive science taught us
The most surprising thing we found designing Nowledge Mem was not a functional mapping between human cognition and software. It was a constraint mapping.
Human attention is limited. So is the context window. Humans need offline consolidation (we call it sleep). So do AI systems (we call it background pipelines). Human storage is cheap but recall is expensive. Same for vector databases with poor recall@k. Humans need active forgetting. So do memory systems drowning in noise.
These are not analogies. They are the same information-theoretic bottlenecks in different substrates.
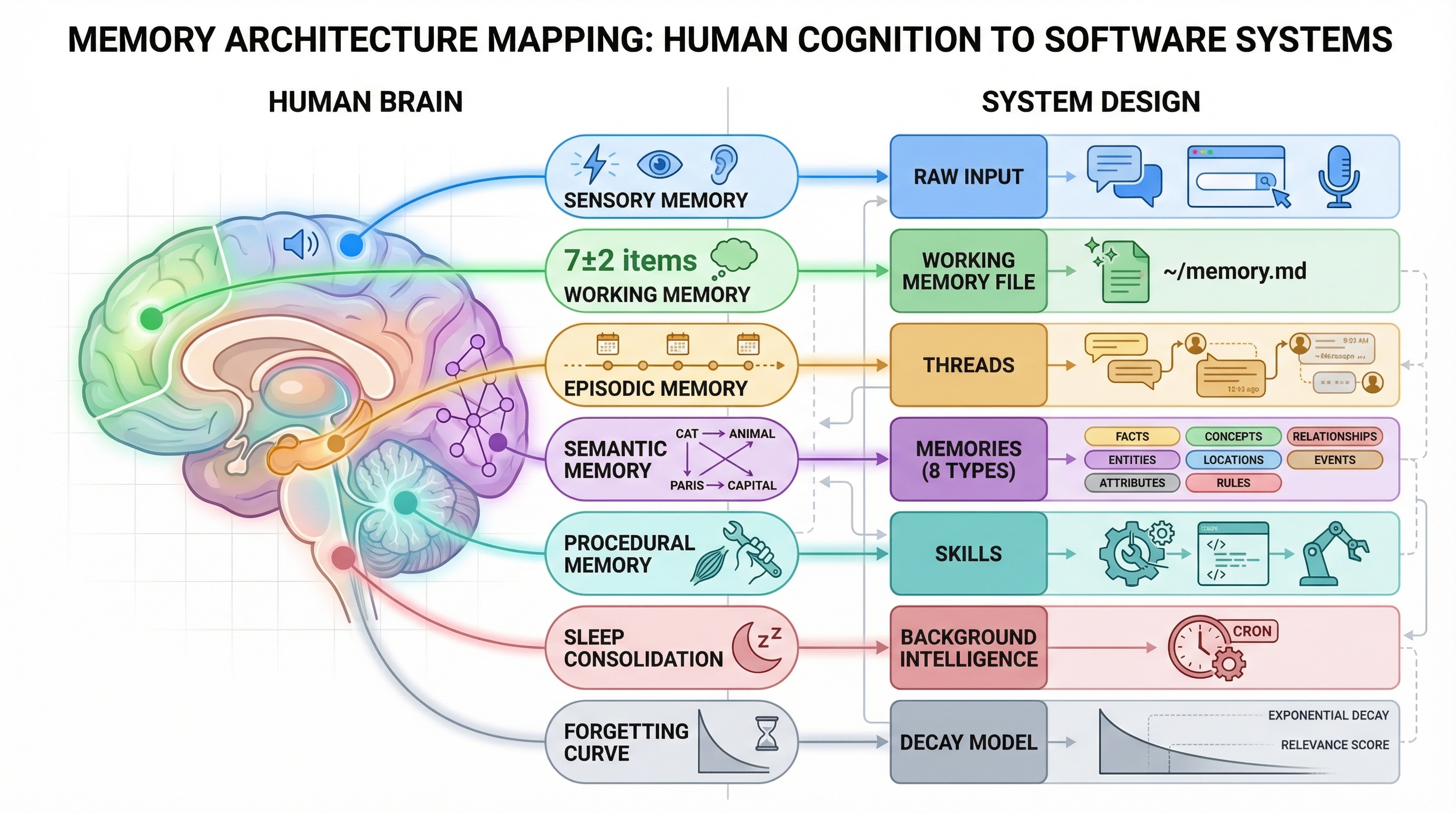 Cognitive mapping: constraints between human cognition and AI memory architecture
Cognitive mapping: constraints between human cognition and AI memory architecture
One concept was especially useful: Working Memory as attention prefetch. Inspired by Baddeley’s model (limited capacity, attention-focused, bridging short-term and long-term), we built a daily Working Memory that a background agent curates from 10K+ memories. It picks the few most relevant items for today, using community signals, decay scores, and recent activity. Think of it as an L1 cache, but for human attention.
The output is a plain Markdown file (~/ai-now/memory.md) that any agent can read. It rotates daily. One user told us: “Every morning, the first thing I do is check the morning briefing.”
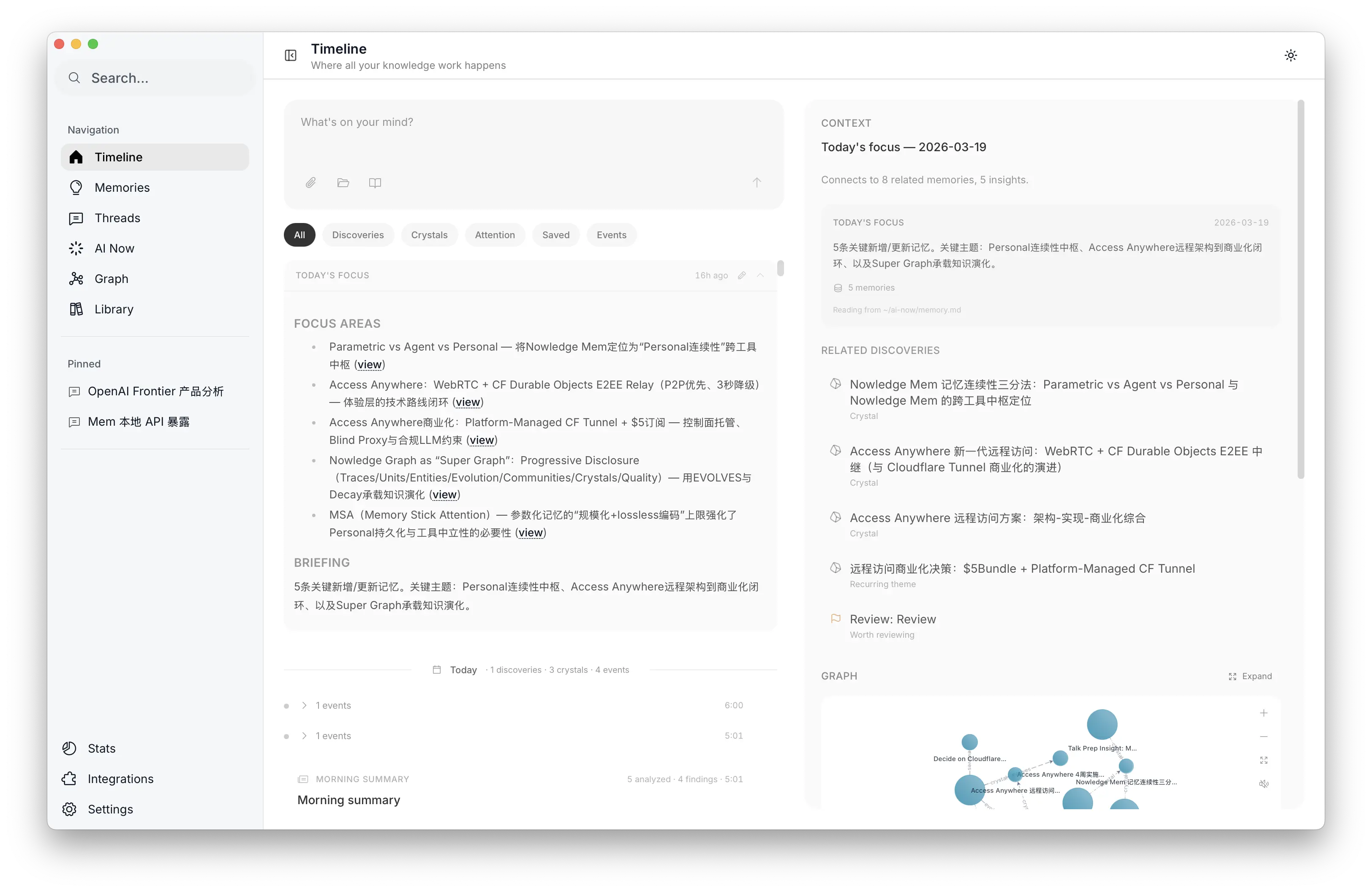 Working Memory in the desktop app
Working Memory in the desktop app
Five challenges
Every memory system eventually hits the same five problems. Here is how we think about each one.
1. Distillation: 90% of conversations are not worth remembering
The question is not whether to remember. It’s in what form.
“Important to the agent” does not equal “important to the person.” “Not important now” does not equal “not important later.” A save/discard binary is the wrong abstraction.
We decompose knowledge into three forms:
- Trace: the raw conversation, preserved in full
- Unit: extracted atomic knowledge (facts, decisions, plans, procedures) that is searchable, linkable, and evolvable
- Crystal: stable conclusions cross-validated by 3+ independent sources
This maps directly to episodic-to-semantic consolidation in cognitive science. From high fidelity to high density.
The design insight that mattered most: type determines evolution pattern. We classify Units into 8 types (fact, decision, plan, procedure, preference, and more). A plan becomes a decision. A decision hardens into a fact. This is not just tagging. It is the knowledge lifecycle.
Three engineering choices made the biggest difference:
Triage gate (~50 tokens). Early on, we distilled every conversation. Token waste was bad. Now a lightweight pre-filter decides whether a conversation is worth the full extraction pipeline. Cost dropped by an order of magnitude.
User intent as architecture. Background auto-distillation uses strict quality thresholds to save cost. But when a user explicitly triggers distillation, that is product intent, and it must flow all the way into the LLM prompt. We learned this from a real postmortem: ignoring user intent in auto-capture led to silent quality drops.
Auto-labeling from existing taxonomy. The agent picks from your existing labels. It never invents new categories. Your label system is yours. The system learns to use it.
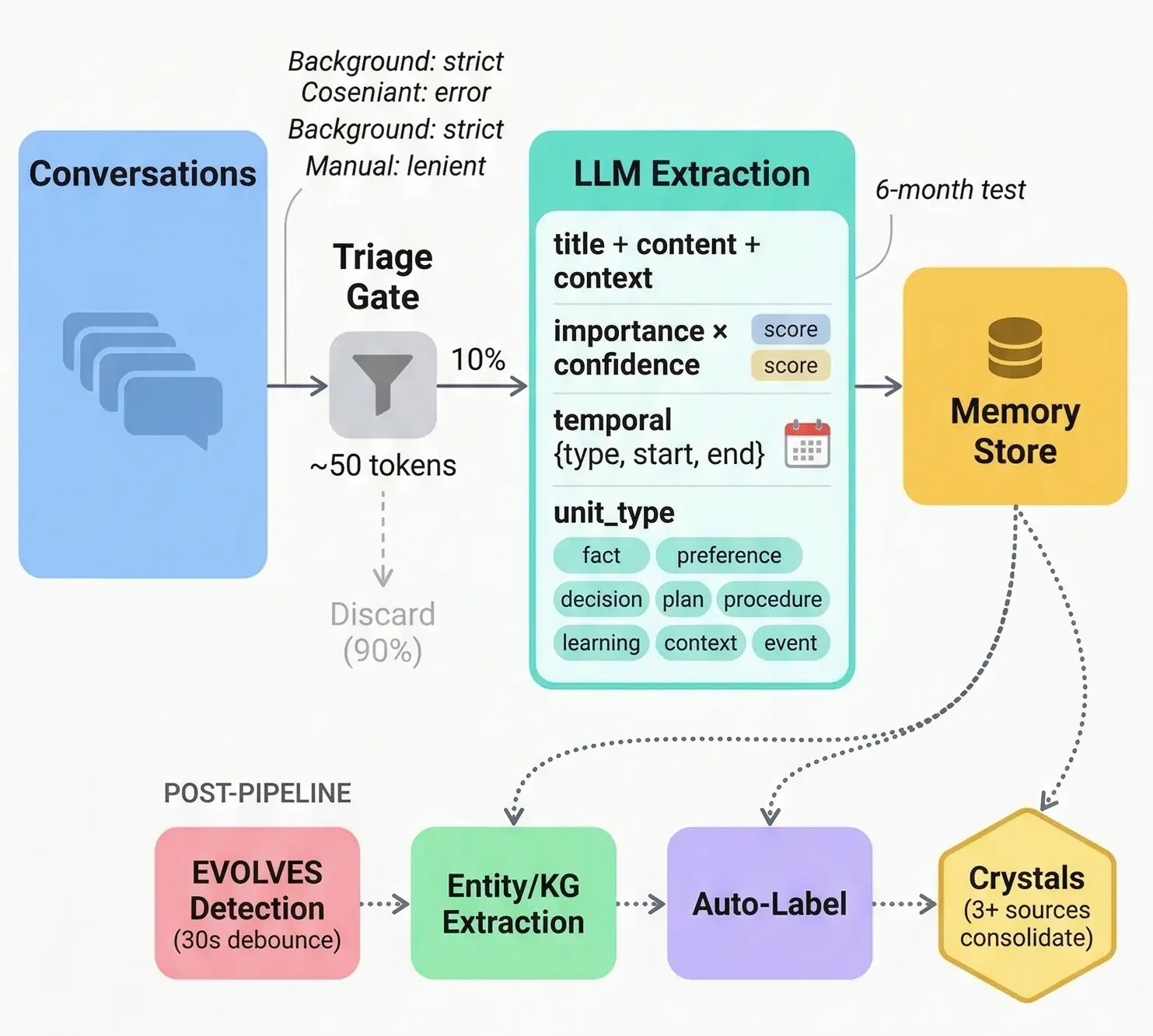 Memory distillation pipeline: from conversation to structured knowledge
Memory distillation pipeline: from conversation to structured knowledge
2. Retrieval: remembering is useless if you can’t find it
The bottleneck is not speed. It is the semantic gap between how you ask and how things are stored.
We built a two-tier retrieval pipeline:
Fast path (~100ms, handles 90% of queries). Vector search + full text search + entity matching + community detection + label filtering + graph traversal, all in parallel. Multi-source hits get a +5% boost. Crystals get +25%. Latest versions get +15%.
Deep path (for the hard 10%). LLM intent classification routes queries into 5 intent types, each with different weight distributions. Concept queries lean 60% vector. Fact queries lean 50% FTS. HyDE bridges expression gaps. LLM reranking blends 0.7 LLM score with 0.3 semantic score. GraphRAG fills in reasoning gaps.
Every result carries a source_thread_id. If an agent needs more context, it pulls the original conversation. You don’t need to stuff everything into the memory. You need good pointers.
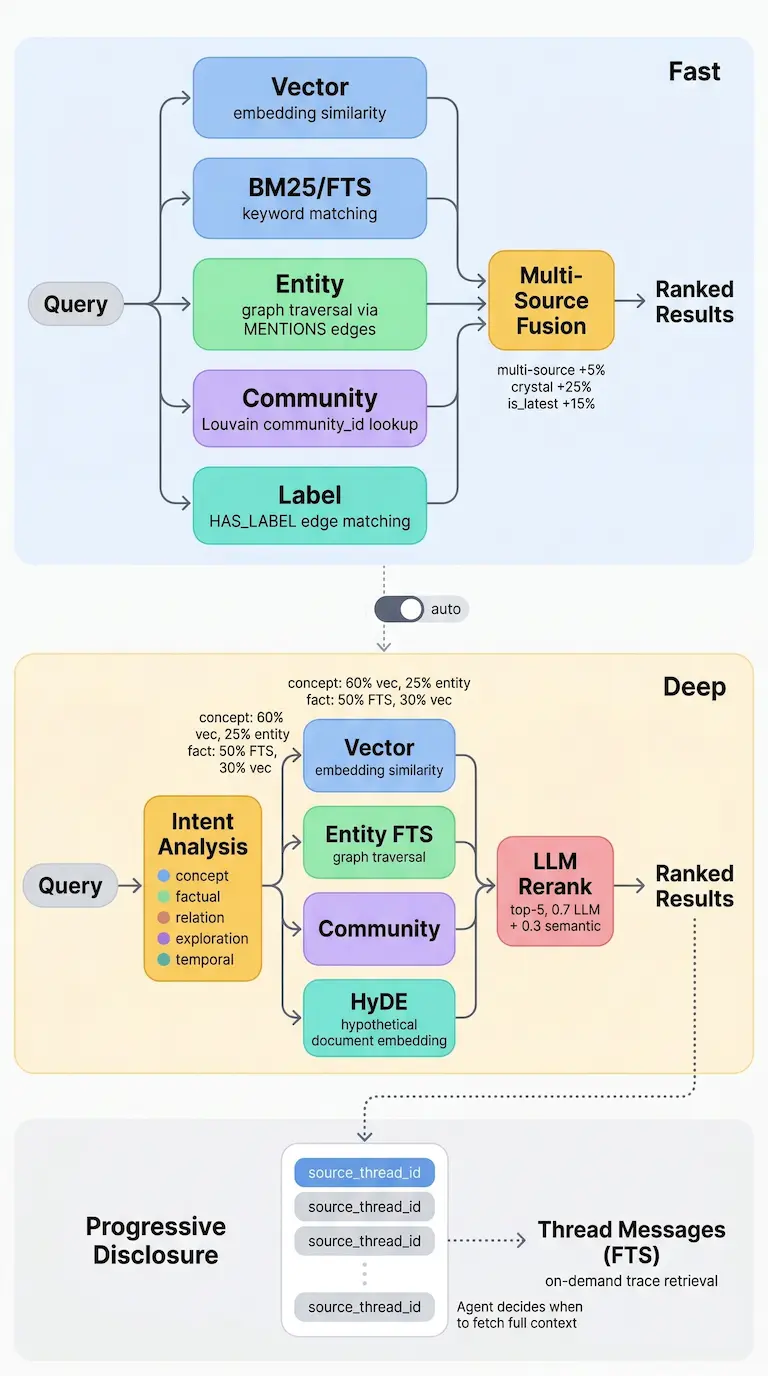 Search pipeline: Fast path and Deep path
Search pipeline: Fast path and Deep path
3. Temporality: memory has two clocks
Most memory systems have one timestamp: created_at. But “what happened in 2020?” and “what did I add this week?” are completely different questions.
We track two independent time dimensions:
- Event time: when the thing happened
- Record time: when we saved it
With precision tracking. If you said “in 2020,” we store 2020-01-01 with precision=year, and the UI shows “2020,” not “January 1st.” If the LLM says “a few years ago” with confidence below 0.3, we don’t store a date at all. We don’t guess.
The retrieval optimization is a three-layer cascade:
- Regex pre-filter (μs). Negative lookahead prevents “last resort” from triggering temporal extraction.
- 3-token LLM gate (~15ms). Yes or no: does this query have temporal intent?
- Full extraction (128 tokens). Type + value + confidence.
90% of queries stop at layer 1 or 2. The expensive third step rarely fires.
In the final ranking formula, temporal boost caps at 0.15 out of 1.0. Semantic similarity dominates at 0.65. Time helps with sorting but does not drive it.
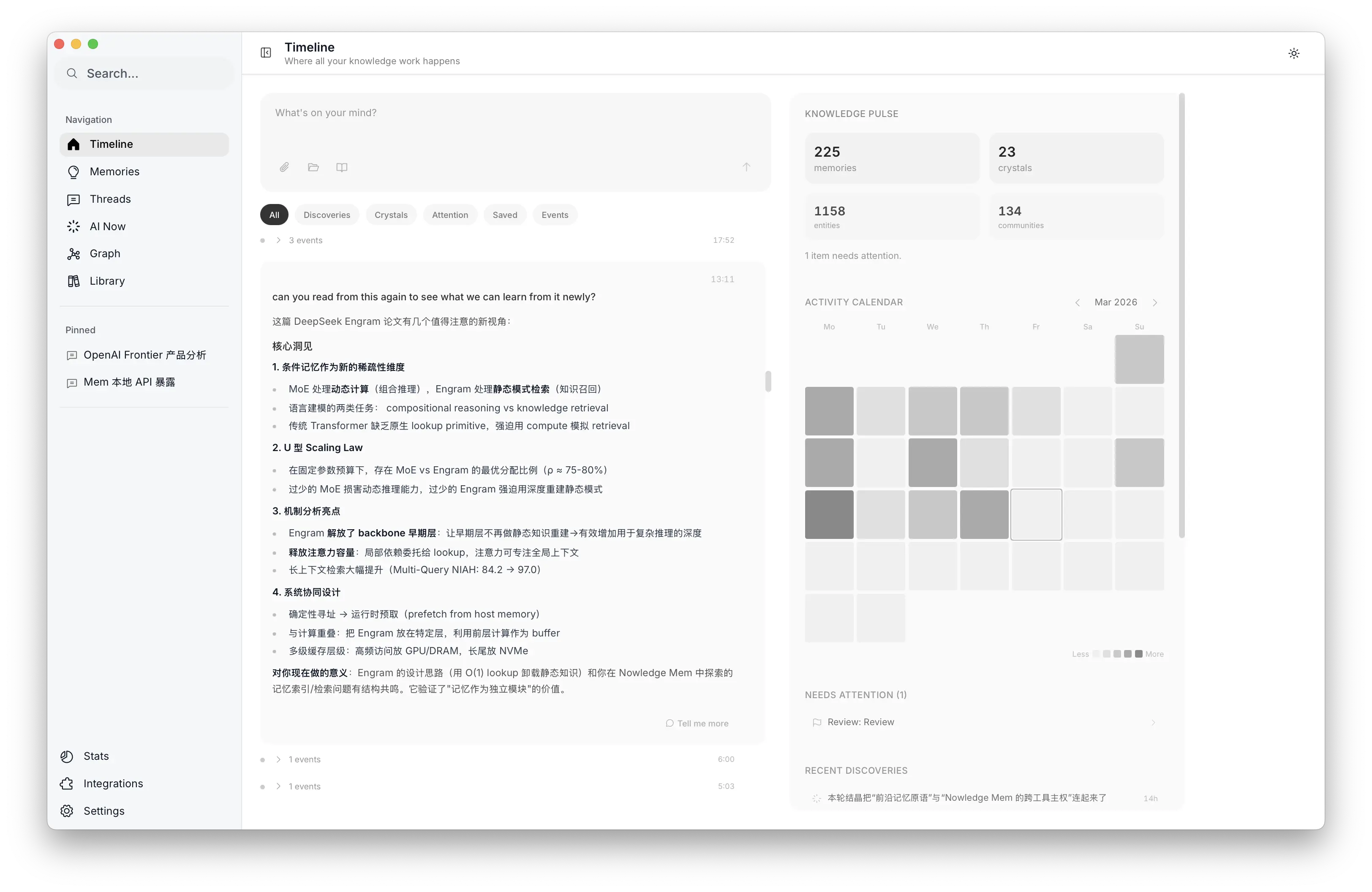 Timeline with bi-temporal Working Memory and activity calendar
Timeline with bi-temporal Working Memory and activity calendar
4. Evolution: knowledge can’t be append-only
Real knowledge changes. You learn something that contradicts what you knew before. A plan becomes a decision. An assumption gets confirmed.
We model this with four evolution relationships. Engineers tend to get this fast because it maps to Git:
| Relationship | Meaning | Git analogy |
|---|---|---|
replaces | New understanding supersedes old | force push |
enriches | Adds to existing knowledge | merge |
confirms | Independent source validates | approve |
challenges | Contradictory information appears | conflict |
A single edge property, is_progression, separates version chains (replaces/enriches = true) from validation signals (confirms/challenges = false). More expressive and more compact than four independent edge types.
The knowledge transformation pipeline (Trace → Unit → Crystal) is not just version control. Crystal formation requires 3+ sources. 2 is coincidence, 3 is a pattern. Insights have three code-level quality gates: empty ones don’t ship, evidence-free ones don’t ship, ones under 30 characters don’t ship.
Why code-level? Because LLM quality degrades. A prompt that says “don’t emit empty insights” can be ignored by a weaker model. if zero_insights: return None never degrades.
When contradictions appear, the system does not auto-resolve. It surfaces both versions side by side, and the user decides: keep the new one, keep both, or dismiss.
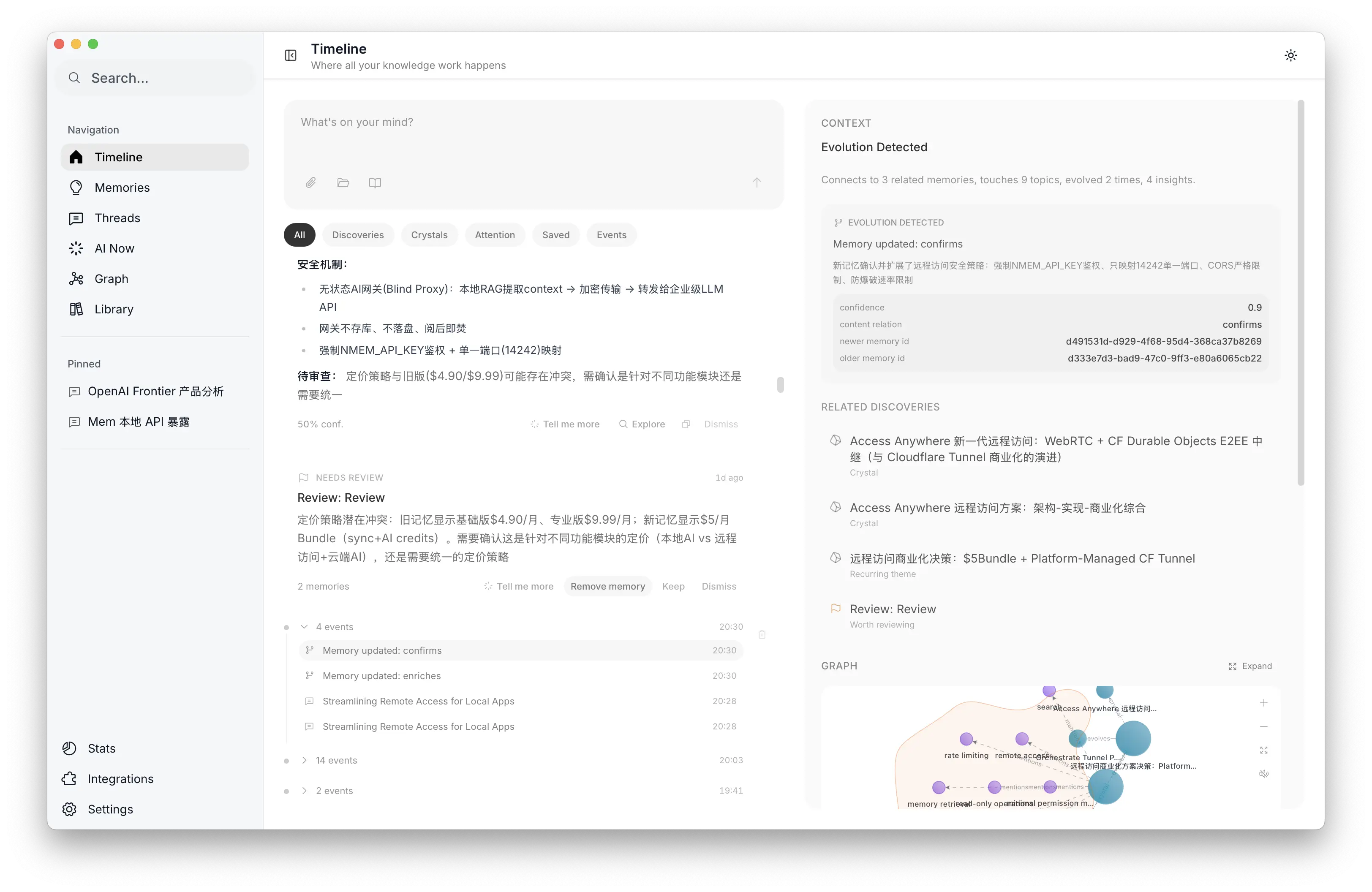 Evolution detection in Timeline and version history with human resolution
Evolution detection in Timeline and version history with human resolution
5. Decay: forgetting is a feature
Most memory systems ignore this one. Without forgetting, a memory system is a landfill.
We looked at two frameworks:
- ACT-R (John Anderson, Carnegie Mellon): decades of work on how the brain activates and forgets memories
- FSRS (Jarrett Ye 叶峻峣): computes optimal review intervals, now the default algorithm in Anki
Both are good. But they solve different problems. FSRS optimizes “do I still remember this?” and needs explicit user ratings (1 to 5). Our problem is “what deserves attention right now?” in a passive retrieval context with no feedback loop.
So we split into two independent scores:
Decay fades over time. Exponential decay with logarithmic frequency correction. Memories naturally dim.
Confidence only goes up. Every search hit, every click, every EVOLVES relationship, every Crystal citation accumulates evidence. confidence = max(new_value, old_value). It never decreases.
Importance floor. Critical memories (decisions, key insights) have a minimum score. Even after months of inactivity, they stay retrievable.
Instead of explicit ratings, we use 6 implicit behavioral signals: search hits, result impressions, click-throughs, reading dwell time, EVOLVES relationships, and Crystal citations. EVOLVES carries the highest weight because knowledge graph validation is the strongest confidence signal we have.
Archival requires all four conditions: decay extremely low, zero interactions, more than 90 days old, and still in active status. The system errs on the side of keeping things.
“A memory system without forgetting is a landfill.”
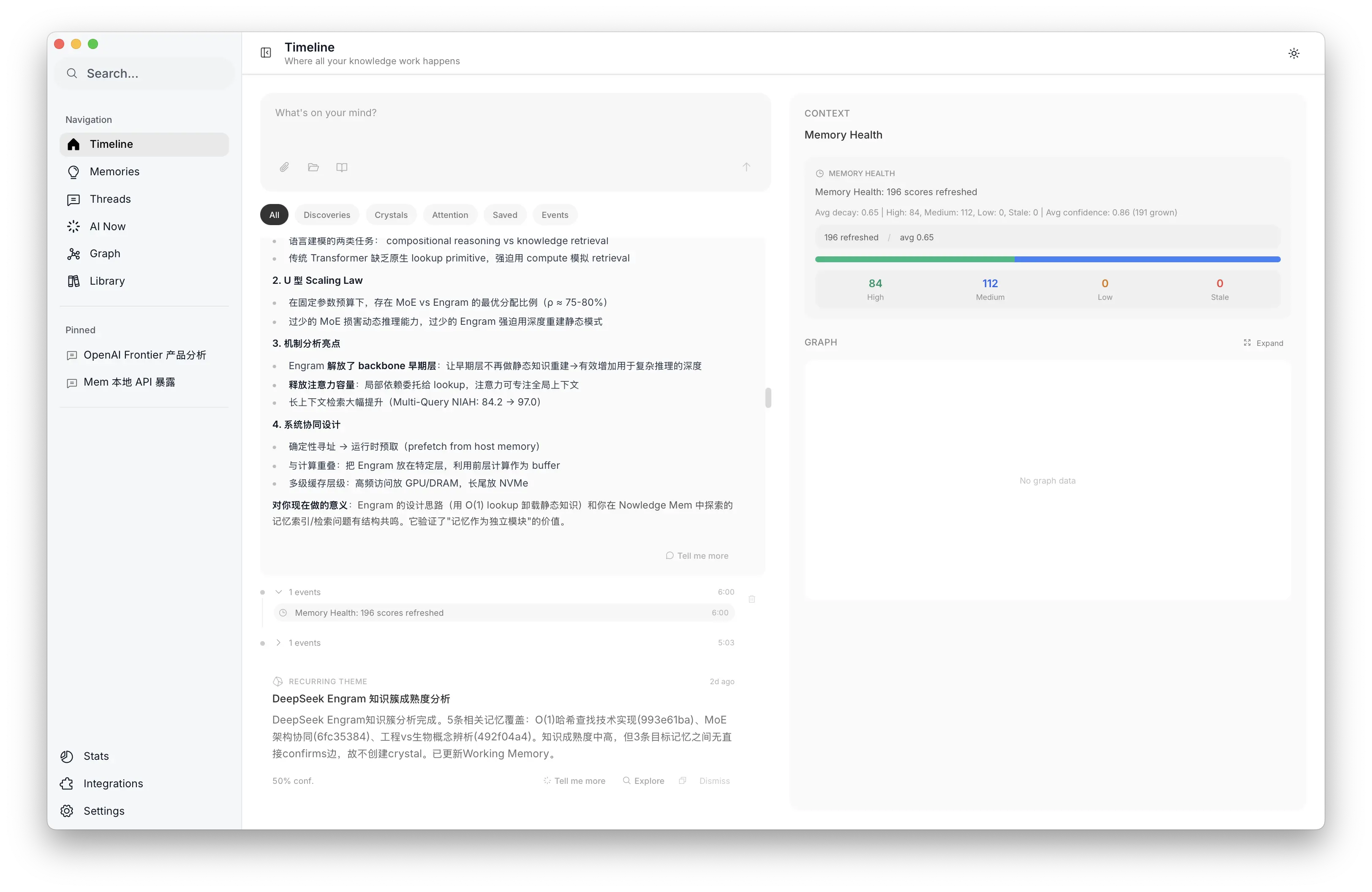 Memory Health dashboard: decay distribution and confidence trends
Memory Health dashboard: decay distribution and confidence trends
How it all fits together
The super graph
Knowledge in the system exists in three forms (Trace, Unit, Crystal) organized into a graph with 7 node types and 11 edge types.
The graph is designed around progressive disclosure. An agent does not load everything at once. It starts with a lightweight semantic search. Needs more context? Check entity relationships. Needs history? Walk the version chain. Needs the big picture? Look at community clusters and Crystal insights.
Each layer has corresponding primitive tools. The knowledge graph is not for visualization. It is for progressive traversal, and every traversal is an act of reasoning.
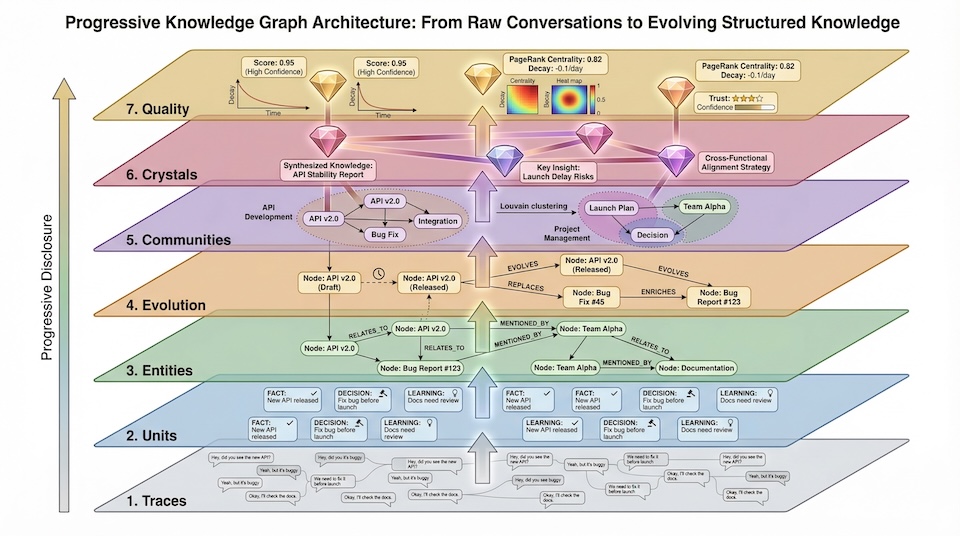 Progressive knowledge graph: from traces to quality layers
Progressive knowledge graph: from traces to quality layers
Background intelligence
EVOLVES detection, entity extraction, Crystal formation, Working Memory curation. All the automatic behavior described above runs as 13 background tasks in two execution models:
Scheduled (cron). 5 AM daily briefing, archive yesterday’s Working Memory, generate today’s. 6 AM decay refresh (pure math, no LLM). Weekly insight detection, Crystal audits, low-activity compaction. Every two weeks: Louvain community detection with AI summaries.
Event-driven (cascade). A new memory triggers three pipelines at once. EVOLVES detection (30s debounce), KG entity extraction (30s), Working Memory refresh (300s). If EVOLVES finds 3+ related memories, it triggers Crystal evaluation automatically. This is cascade, not scheduling.
Before any task runs, context injection pre-computes what the agent needs: 48-hour activity summaries, graph statistics, yesterday’s Working Memory. Hard cap at ~25K tokens. The agent does not explore. Every token goes to decision making.
Four layers of guardrails keep costs and noise down:
- Debounce: 30s/300s to merge burst events
- Rate limit: 15 tasks/hour, excess queued (never dropped)
- Token budget: per-task + per-hour + per-day caps
- Quality gate: code-level. Empty briefings get swallowed, no event generated
Control
A memory system without a sense of control is just a database. We think about control in five dimensions:
- Visible. Graph visualization, version history, community clustering.
- Operable. Edit, delete, resolve contradictions, manage labels.
- AI-native. Natural language scheduling of any knowledge task. “Clean up low quality memories.” “Analyze my React knowledge distribution.”
- Data sovereignty. Local storage, non-binary formats, full export anytime, rich API including graph visualization endpoints.
- Ubiquitous. Desktop, iOS, Android, TUI, CLI, MCP.
The logic is straightforward. If you can’t see it, you won’t trust it. If you don’t trust it, you won’t use it. And if you don’t use it, it’s the same as not having it.
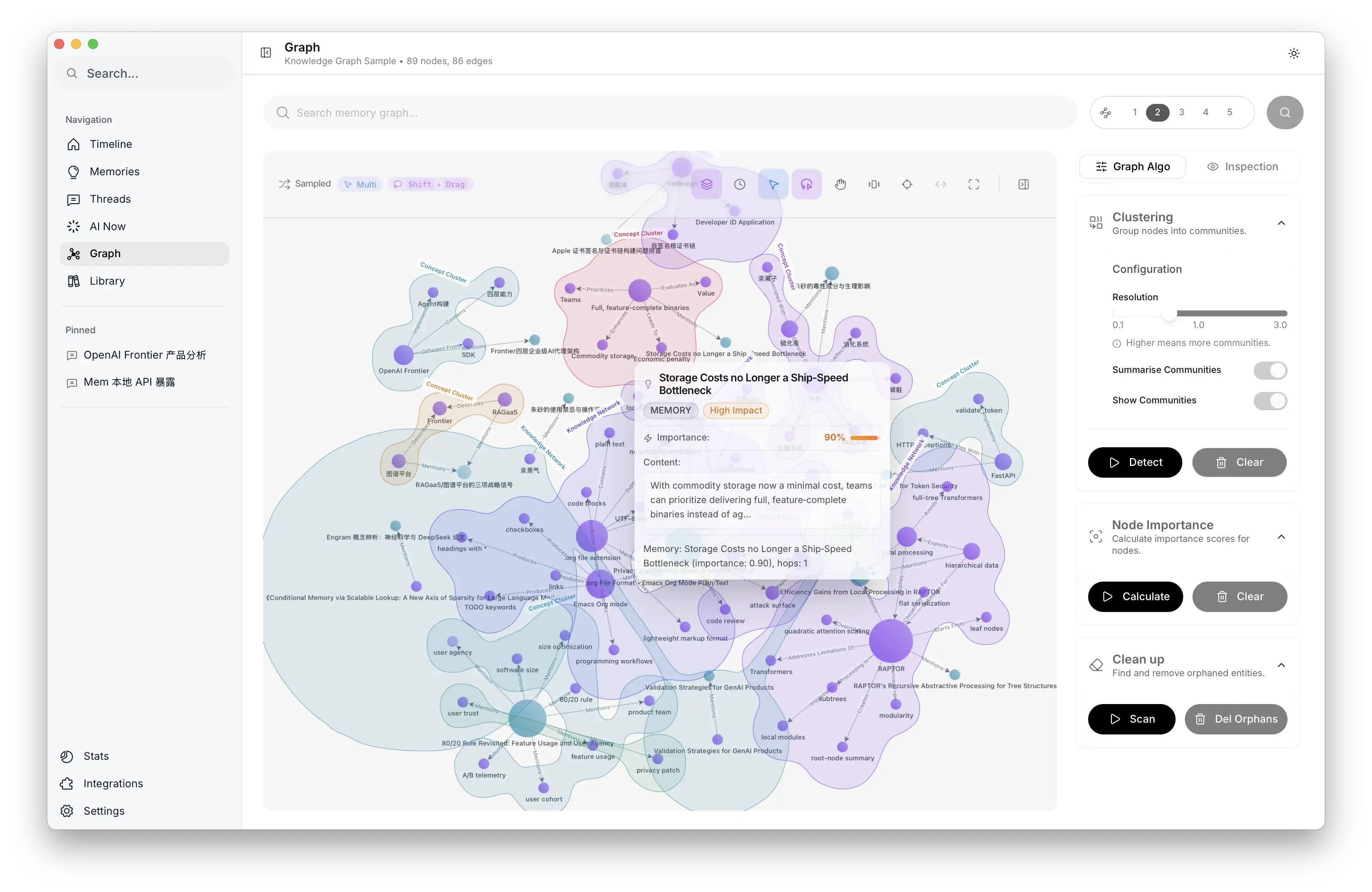 Graph exploration: community clustering, node importance, and global analysis
Graph exploration: community clustering, node importance, and global analysis
The connection layer
Building the memory system was one thing. Connecting it to every tool people actually use was harder.
8 native plugins: Claude Code, Cursor, Codex, Gemini CLI, OpenClaw, Bub, Alma, Droid. A browser extension auto-syncing conversations from 14 AI platforms. Native connectors for Obsidian, Apple Notes, Notion. Desktop, iOS, Android, CLI, Raycast, MCP.
Each plugin has a full lifecycle, not a shallow MCP call. Inject Working Memory at startup, capture knowledge during the session, distill into the graph at the end.
Every tool has its own session model. Claude Code sessions are long conversations. Cursor sessions are short tasks. Browser tabs produce scattered fragments. The connection layer is what makes knowledge flow between all of them.
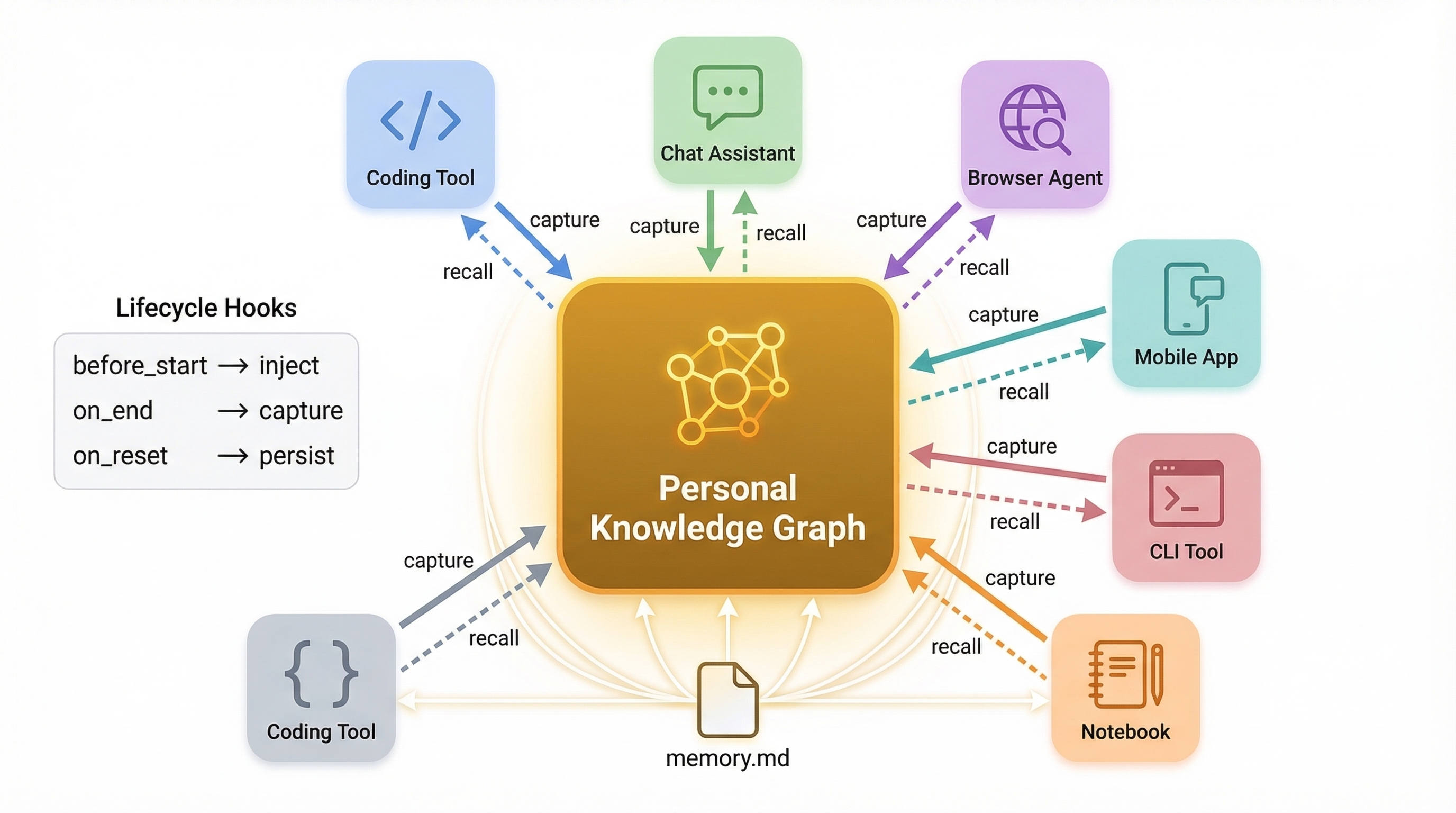 Cross-agent connection layer: personal knowledge graph at the center
Cross-agent connection layer: personal knowledge graph at the center
Four theses after a year
A. Memory is being commoditized. Every AI-native product builds its own memory now. ChatGPT, Claude, Cursor, Gemini. All different, none interoperable. This won’t converge on its own. There needs to be an aggregation layer. Think 1Password for knowledge instead of passwords.
B. Memory outlives tools. How many agent frameworks from 2023 are still around? Langchain, AutoGPT, BabyAGI. Tools get replaced. Memory can’t disappear with them. Local storage, open formats, full export. If users can’t control their data, they won’t trust it.
C. Memory is an intelligence problem, not a storage problem. All five challenges reduce to this. Distillation is classification. Retrieval is ranking. Forgetting is attention allocation. The core of a memory system is not a database. It is a decision chain, and every step requires agent-level judgment.
D. The endgame is executable experience. Memory → Crystal → Skill. Today, CLAUDE.md and SKILLS.md are hand-written formalizations of judgment. Right abstraction, but manual labor. SkillCraft (Chen et al., 2026) showed that tool composition can be cached as reusable skills, cutting tokens by 80%. Yansu (Isoform) goes further: crystallized knowledge becomes executable applications. The next step is letting the system generate these from memory automatically.
What’s next
Learning on graphs. The graph currently handles storage, traversal, and algorithms. Next is GNN-based predictive reasoning on top of it, on-device. Which memories are about to go stale? Which decisions conflict? What cross-domain connections haven’t been surfaced? Moving from reactive Q&A to proactive alerts.
Crystal → Skill automation. The Crystal pipeline already produces raw material for agent skills. SkillCraft and Yansu point the way. Next step is carefully automating this chain: memory → crystallized insight → verified, executable skill.
Adaptive memory architecture. MemEvolve showed that memory architecture itself can evolve. Different users and workflows need different memory strategies, decay parameters, and retrieval preferences. Our direction is letting the system learn each user’s memory style, but with a hard constraint: the user must be able to understand and trust the system’s decisions. Personalized, not fully autonomous.
Based on talks at the vLLM Beijing Meetup and KCD (Kubernetes Community Days), March 21, 2026. Video recordings coming soon. Follow @NowledgeMem for updates.
slides: https://siwei.io/talks/memory-2026/
Nowledge Mem is a local-first, graph-augmented personal context manager for AI agents. Learn more or read the docs.