While we were building Skills, Mem produced its own best demo.
Our development records already live in Mem, the same way any work you connect does. Reading them, it noticed a method we kept using but had never written down, and wrote it up as a Skill, pointing back to the work that earned it. Then we asked the system to improve that Skill. It built a small evaluation from the evidence, tried revisions across two rounds, and kept none of them, because none beat the original.
The refusal is the part we trust most. But the method first.
The method it noticed
Build an evaluation that can fail. Write down what happens at each step. Find the one place the pipeline is actually stuck. Change only that. Run it again.
That sounds obvious. It’s also the first thing people skip when a result looks wrong. The reflex is to tune the prompt, switch the model, move a threshold, or make the system suggest more. It feels busy, but you don’t know which step improved.
We’d used this loop twice in recent weeks. Once on con, a terminal we’re building where an AI agent drives a real shell. The evaluation there started at 5 of 15 cases passing, and what carried it to 15 of 15 wasn’t a stronger model; it was the evaluation itself growing honest enough to show where each failure actually lived. Then again on Mem itself, measuring how many real procedures the Skills pipeline could recall from a graph, making the funnel visible, and fixing one constraint at a time.
Mem found the shared pattern in those records and wrote it as a Skill: build-a-harness-optimize-loop.
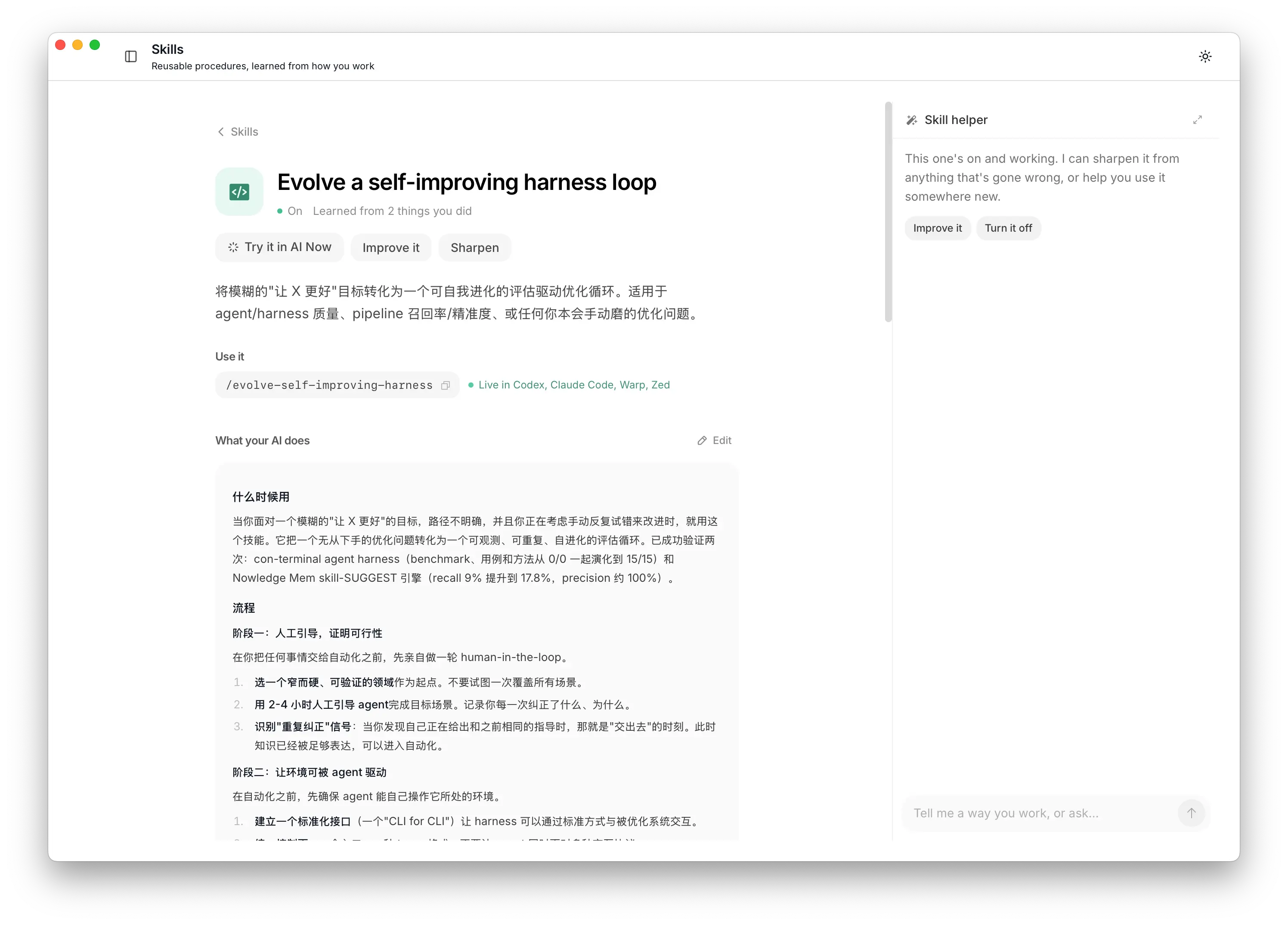 The crystallized harness loop Skill detail
The crystallized harness loop Skill detail
It skipped the empty “use evaluations” advice and wrote the actual moves: what to measure first, why each step needs a trace, when to change only one thing, and when not to scale the run yet. A method from real work, in a form an agent can follow later.
Then it refused to make it worse
We asked Mem to sharpen that Skill.
It derived test cases from the Skill’s own evidence, tried several revisions, and compared each against the current version. Two rounds. Nothing beat the original, so nothing shipped: no pending version, no silent overwrite, no edit made to look like progress.
That result is quiet. It’s also correct. If an article edit is weak, the article is just worse. If a Skill edit is weak, the agent may follow worse instructions next time, because once a Skill is on, agents really do follow it. A self-improving system has to improve, and it also has to know when to stop. No better version, no change.
What counts as a Skill
That episode is the clearest way to explain where we draw the lines in v0.9.
Memories record what happened, what you decided, and what you learned.
“Keep answers short” is a rule. It should shape every run. “Do not hand-edit generated API docs in this project” is also a rule. It constrains behavior.
“When cutting a release, commit the submodules before moving the parent pointer” is a Skill. It changes the order an agent works in. If the agent misses it, the repo ends up in a bad state.
One question decides it: what exactly will the agent do differently next time? If there’s no answer, it shouldn’t become a Skill.
And a Skill earns trust through its source, not its phrasing. Mem looks for repeatable methods in work you actually did: a debugging pass, a release sequence, a review habit, a safety check you only learned after getting it wrong. Each suggestion points back to the moment that earned it. Suggested Skills stay off until you turn them on, because a bad Skill can make the next run worse.
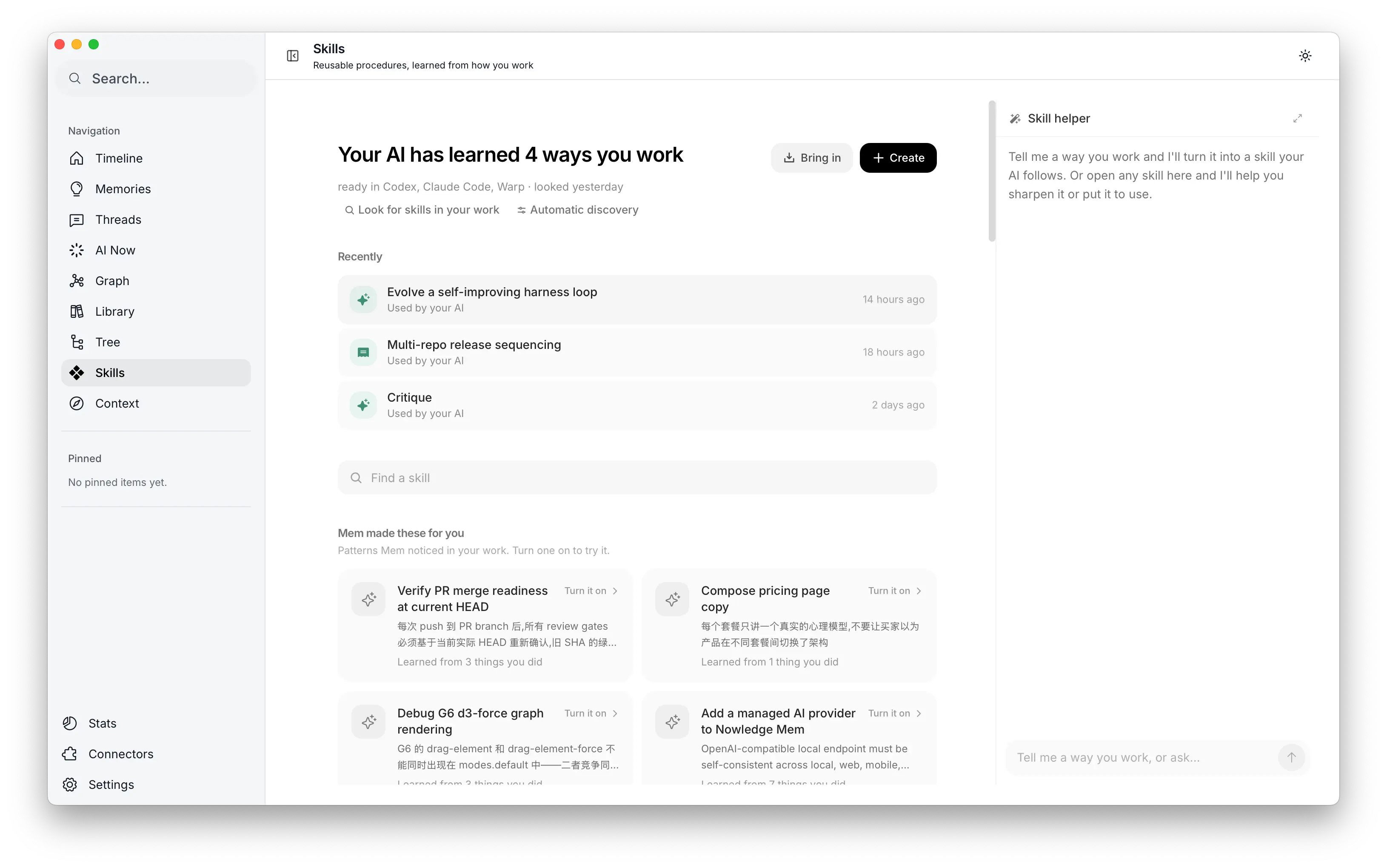 Skills in Nowledge Mem
Skills in Nowledge Mem
What you see in v0.9
AI can write a plausible checklist on almost anything, and most of those checklists aren’t worth keeping; a strong model already knows the generic version. So the Skills page should feel quiet.
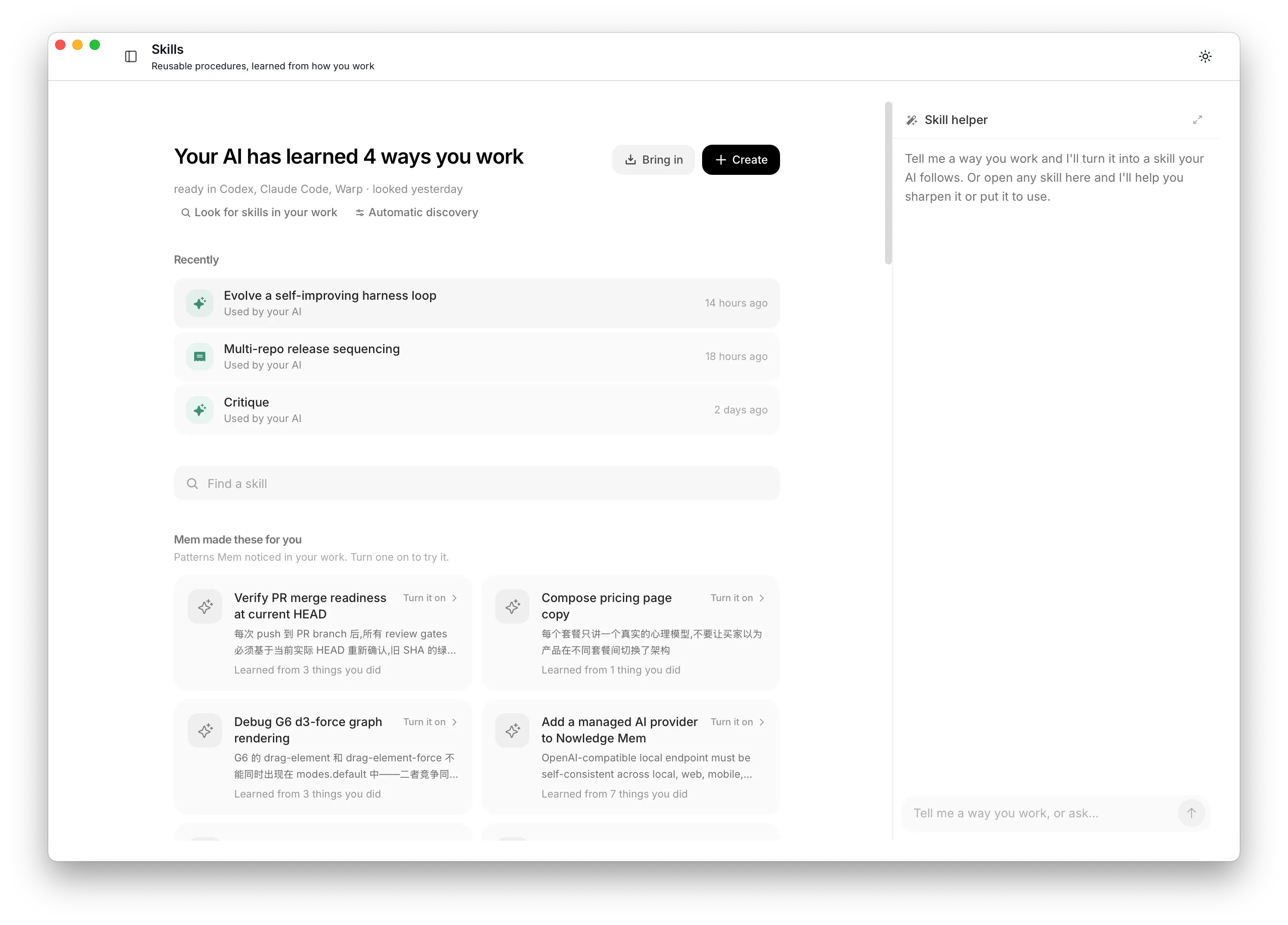 The harness loop Skill in the Skills list
The harness loop Skill in the Skills list
The list should be short. Each suggestion needs a source and three answers:
- What real work did this come from?
- What will the agent do differently after it’s turned on?
- Why does Mem think this is worth keeping?
If you recognize it and trust the evidence, turn it on. Agents connected to Mem can then read it when it applies, and any later refinement faces the same gate: the new version has to prove it’s better.
That’s Skills in v0.9: your own hard-won step, turned into something your agents can reuse. The release it ships in is covered in the v0.9 post.