上周我在 vLLM 北京 Meetup 和 KCD(Kubernetes Community Days)做了这个分享:做 Nowledge Mem 的工程经验。
这篇文章比 slides 更深。如果你在现场,当作补充笔记。如果不在,这篇本身是完整的。
问题
你在 Claude Code 里花两个小时做了一个架构决策。第二天打开 Cursor,它对那个决策一无所知。
这就是 2026 年 AI 记忆的现状。每个工具各做各的:ChatGPT 存键值对,Claude 用文件系统,Cursor 用 glob 规则。互不相通。一个重度用户每天用 4、5 个 AI 工具,每个都以为自己是唯一的。
问题不是 AI Agent 要不要记忆。是要什么样的记忆,以及怎么建,才不至于最后变成一个垃圾抽屉。
三种范式
说到「AI 记忆」,不同的人指的是完全不同的东西。
参数记忆把知识编进模型权重。KBLaM(Microsoft, 2025)和 MSA(EverMind, 2026)走的是这条路,通过微调和权重级别的集成。这是模型层面的事。
Agent 记忆让 Agent 有跨会话的持久性。大部分精力投在这里,后面要讨论的挑战大多从这里来。
记忆即产品是我们所在的层。它继承了 Agent 记忆的所有挑战,还多出来几个:跨工具连续性、时间推理、知识演化,再加一个很实际的问题:用户凭什么信任一个 AI 系统来管他的知识。
设计思路的演进
过去三年,这个领域走了四个阶段:
- 认知模拟(2023)。Generative Agents 引入了 memory stream + reflection。Voyager 把可执行代码存成 skill。第一批认真做记忆巩固的工作。
- OS 隐喻(2023–25)。MemGPT 的类比最干净:context 是 RAM,LLM 是 CPU。MemOS 把它扩展到可调度的记忆资源。
- 数据基础设施(2024–25)。很多项目证明了这不只是学术问题。Zep 做了 temporal KG。AWS AgentCore 把基础能力商品化了。
- 可学习记忆(2025–26)。A-MEM 自组织索引(Zettelkasten 风格)。MemSkill 用 PPO 学习操作策略。MemEvolve 连架构一起进化。
方向是一致的:关于记忆结构和演化的决策权在持续从人转向 Agent。四个阶段共享一个假设:记忆服务于 Agent。
认知科学给我们的启发
设计 Nowledge Mem 的时候,我本来以为收获最大的会是功能上的对应,也就是人类认知的哪些能力对得上软件的哪些模块。结果真正有用的是约束的映射。
人的注意力有限,context window 也有限。睡眠是离线巩固,后台 pipeline 也是。人脑存得便宜、取得费劲,向量数据库的 recall@k 同样很差。而且两边都得主动遗忘:被噪声淹没的记忆系统,和被信息过载的大脑没两样。
这些不是类比。是同样的信息论瓶颈,在不同基底上反复出现。
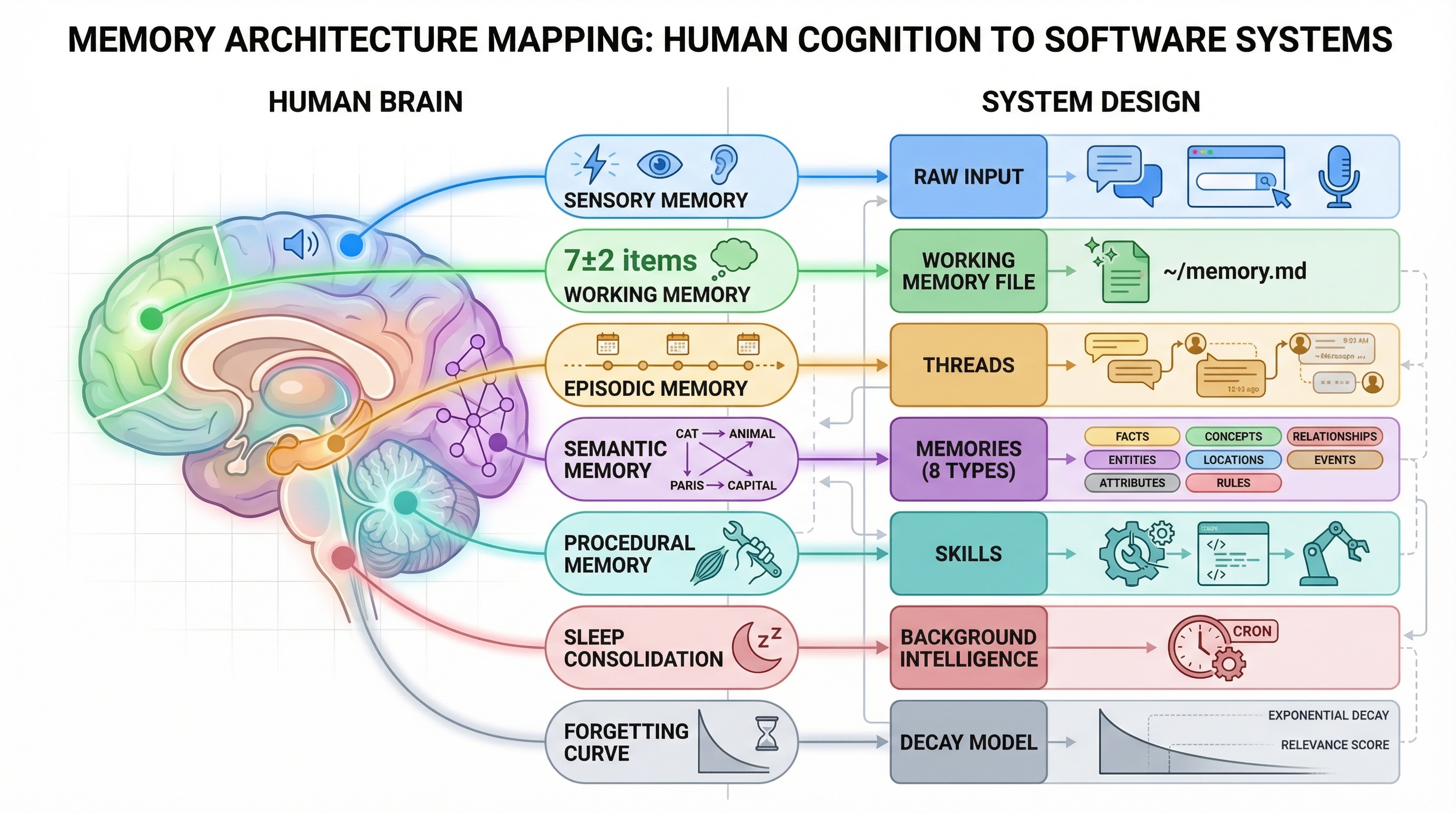 认知映射:人类认知与 AI 记忆架构之间的约束对应
认知映射:人类认知与 AI 记忆架构之间的约束对应
有一个概念特别有用:Working Memory 作为注意力预取。灵感来自 Baddeley 的工作记忆模型(容量有限、注意力聚焦、桥接短期和长期),我们做了一个每日的 Working Memory,由后台 Agent 从 10K+ 条记忆中筛选出来。它挑今天最相关的几条,参考社区信号、衰减分数和近期活跃度。你可以把它理解为 L1 cache,但面向的是人类注意力。
输出是一个纯 Markdown 文件(~/ai-now/memory.md),任何 Agent 都可以直接读。每天轮换。有用户跟我们说:「每天早晨第一件事就是看 morning briefing。」
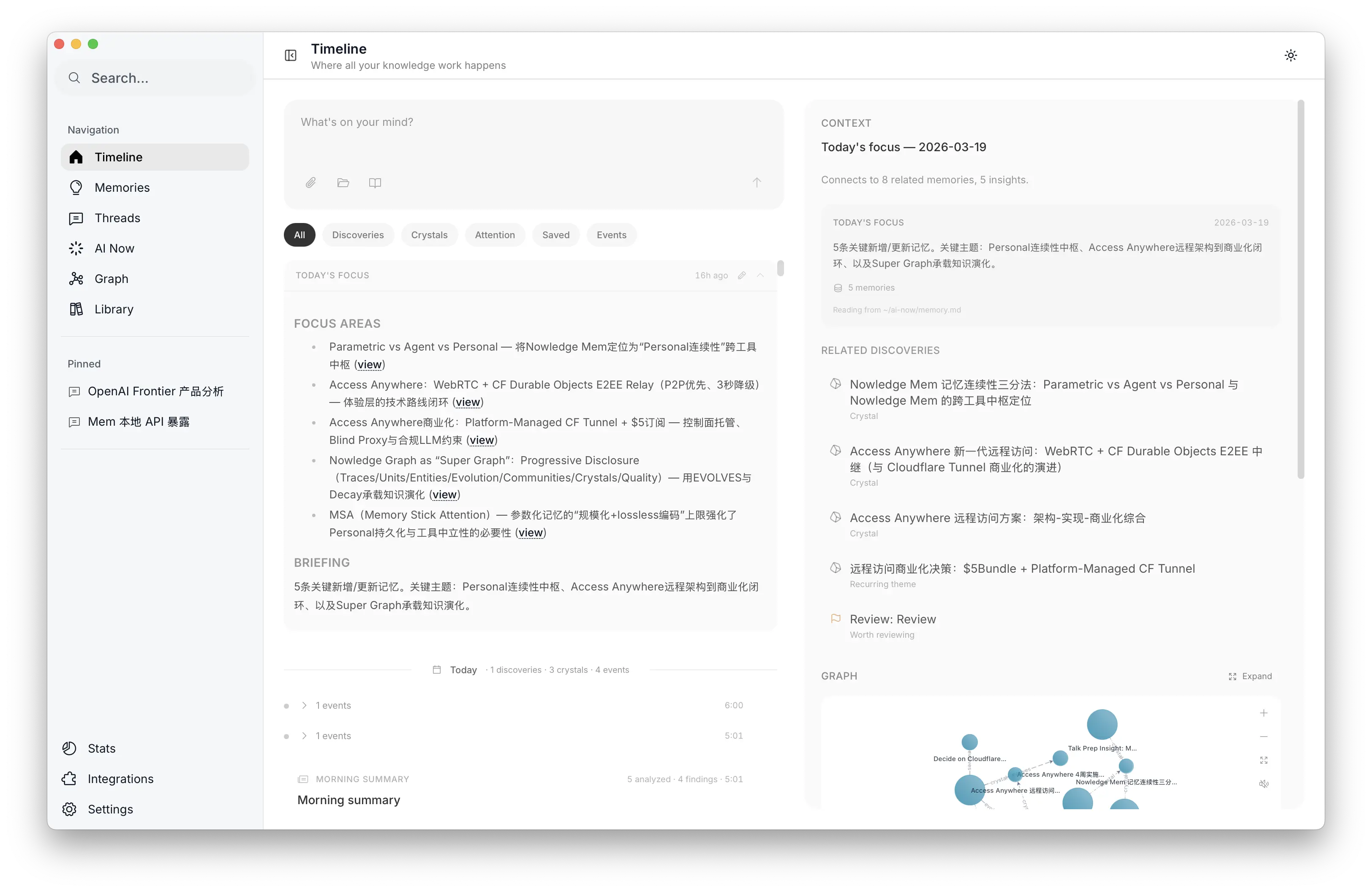 桌面端 Working Memory 界面
桌面端 Working Memory 界面
五个核心挑战
每个记忆系统最终都会撞上同样的五个问题。
1. 蒸馏:90% 的对话不值得记
问题不是「要不要记」,而是「以什么形态记」。
「对 Agent 重要」不等于「对人重要」。「现在不重要」不等于「以后不重要」。save 和 discard 的二选一是错误的抽象。
我们把知识分解成三种形态:
- Trace:原始对话,完整保留
- Unit:提取的原子知识(fact、decision、plan、procedure),可搜索、可关联、可演化
- Crystal:3+ 个独立来源交叉验证后的稳定结论
这直接对应认知科学中 episodic 到 semantic 的巩固过程。从高保真到高密度。
最关键的设计洞察:type 决定演化模式。我们给 Unit 分了 8 种类型(fact、decision、plan、procedure、preference 等)。plan 会变成 decision,decision 会固化为 fact。这不只是打标签,是知识的生命周期。
三个工程决策影响最大:
Triage gate(约 50 tokens)。早期我们蒸馏每一条对话,token 浪费很严重。现在一个轻量预过滤器先判断对话是否值得进完整的提取管线。成本降了一个数量级。
用户意图即架构。 后台自动蒸馏用严格的质量门槛来省成本。但当用户主动点了蒸馏,那是产品意图,必须贯穿到 LLM prompt 里。这是一次真实 postmortem 的教训:在自动捕获中忽略了用户意图,导致质量悄悄下降。
从已有分类中自动标注。 Agent 从你已有的标签里选,不会发明新分类。你的标签体系是你自己建的,系统只是学着用。
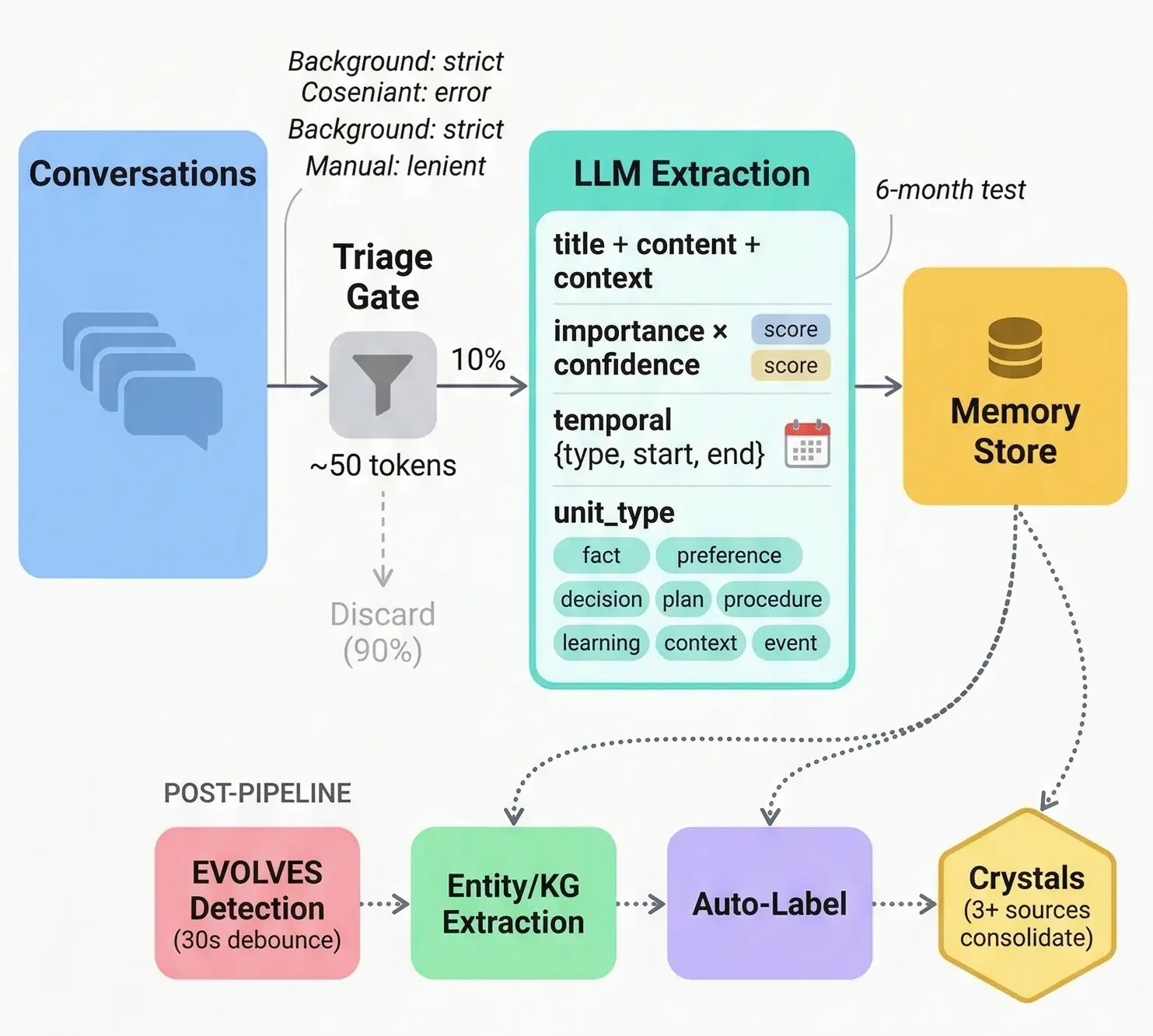 记忆蒸馏管线:从对话到结构化知识
记忆蒸馏管线:从对话到结构化知识
2. 检索:记住了找不到,等于没记
速度不是瓶颈。真正难的是 query 和记忆之间的语义鸿沟。
我们做了一个两级检索管线:
快路径(约 100ms,处理 90% 的查询)。向量搜索 + 全文搜索 + 实体匹配 + 社区检测 + 标签过滤 + 图谱遍历,并行执行。多源命中 +5% boost,Crystal +25%,最新版本 +15%。
深路径(处理难的 10%)。LLM 意图分类把查询路由到 5 种意图类型,每种有不同的权重分配。概念类查询偏 60% 向量,事实类查询偏 50% 全文搜索。HyDE 桥接表述差异。LLM rerank 按 0.7 LLM 分数 + 0.3 语义分数混合。GraphRAG 补充推理能力。
每条结果带 source_thread_id。Agent 需要更多上下文时,直接拉原始对话。记忆不用塞所有东西,有好的指针就够了。
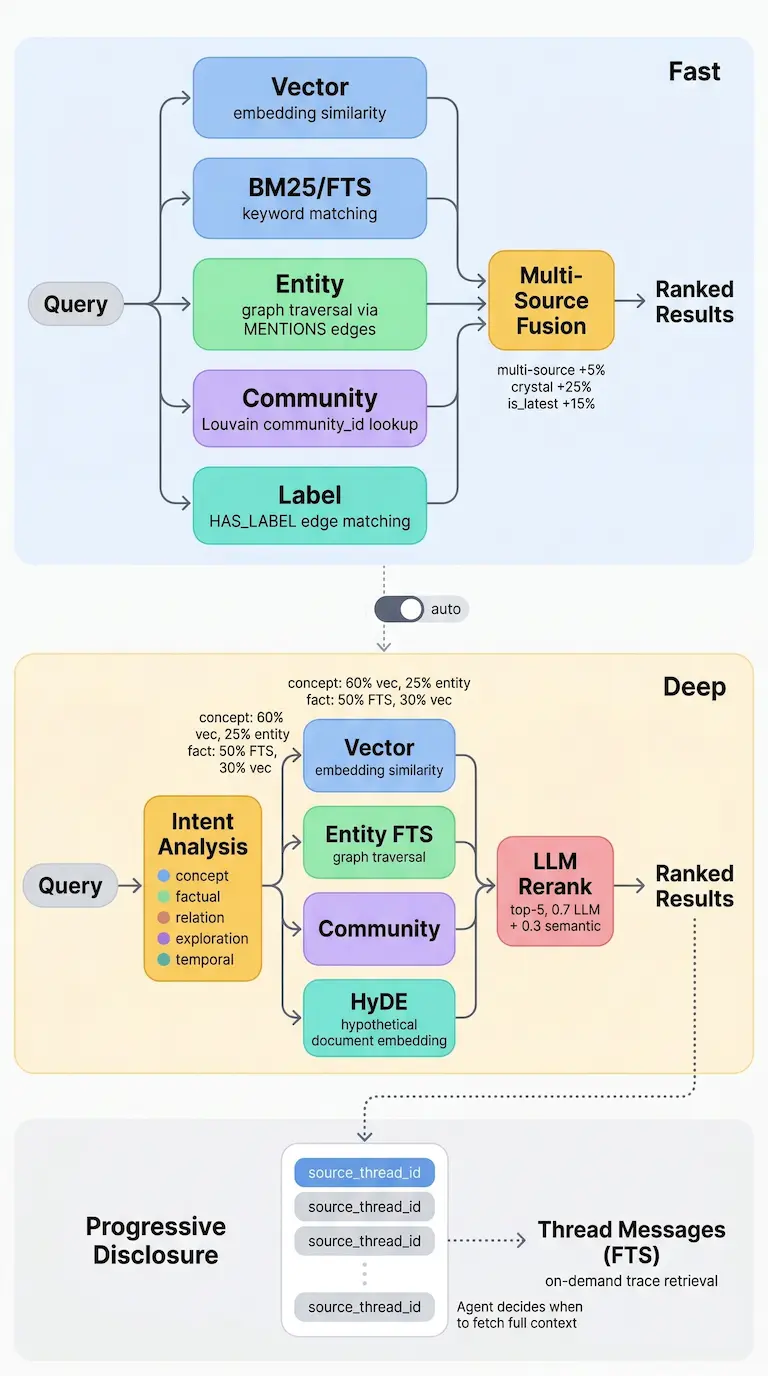 搜索管线:快路径与深路径
搜索管线:快路径与深路径
3. 时间:记忆有两个时钟
大部分记忆系统只有一个 created_at。但「2020 年发生了什么」和「这周加了什么」是完全不同的问题。
我们追踪两个独立的时间维度:
- 事件时间:事情发生的时候
- 记录时间:我们保存的时候
配合精度追踪。你说「2020 年」,我们存 2020-01-01 + precision=year,UI 显示「2020」而不是「1 月 1 日」。LLM 说「前几年」,confidence 低于 0.3,直接不存日期。不猜。
检索优化是一个三层级联:
- 正则预过滤(微秒级)。negative lookahead 防止「last resort」误触发时间提取。
- 3-token LLM 门控(约 15ms)。yes or no:这个查询有没有时间意图?
- 完整提取(128 tokens)。type + value + confidence。
90% 的查询在第 1 层或第 2 层就结束了。昂贵的第 3 步很少触发。
最终排序公式中,时间 boost 上限 0.15(满分 1.0)。语义相似度主导,权重 0.65。时间辅助排序,但不驱动排序。
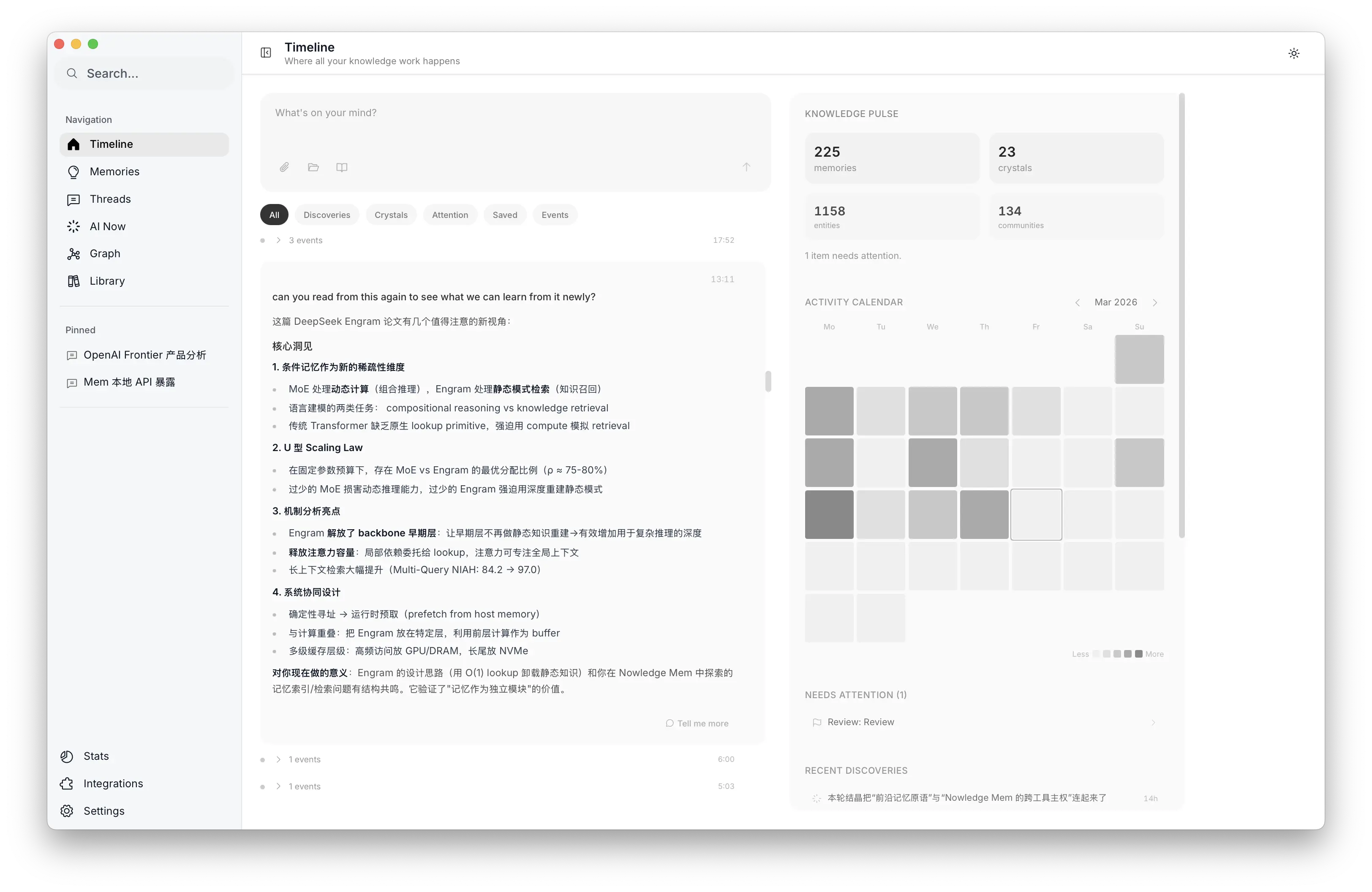 Timeline:双时态 Working Memory 与活动日历
Timeline:双时态 Working Memory 与活动日历
4. 演化:知识不能只增不变
真实的知识会变。你学到了和之前矛盾的东西。一个 plan 变成了 decision。一个假设被验证了。
我们用四种演化关系来建模。工程师一般秒懂,因为能直接映射到 Git:
| 关系 | 含义 | Git 类比 |
|---|---|---|
replaces | 新理解取代旧理解 | force push |
enriches | 补充已有知识 | merge |
confirms | 独立来源验证 | approve |
challenges | 矛盾信息出现 | conflict |
一个边属性 is_progression 把版本链(replaces/enriches = true)和验证信号(confirms/challenges = false)分开。比四种独立的边类型更有表达力,也更紧凑。
知识转化管线(Trace → Unit → Crystal)不只是版本控制。Crystal 形成要求 3+ 个来源:2 个是巧合,3 个是模式。Insight 有三层代码级质量门控:空的不发、没有证据的不发、少于 30 字的不发。
为什么是代码级?因为 LLM 的质量会退化。prompt 里写了「不要发空 insight」,弱模型可能忽略。if zero_insights: return None 永远不会退化。
矛盾出现时,系统不自动解决。把两个版本并排展示,用户来决定:保留新的、都保留、或者忽略。
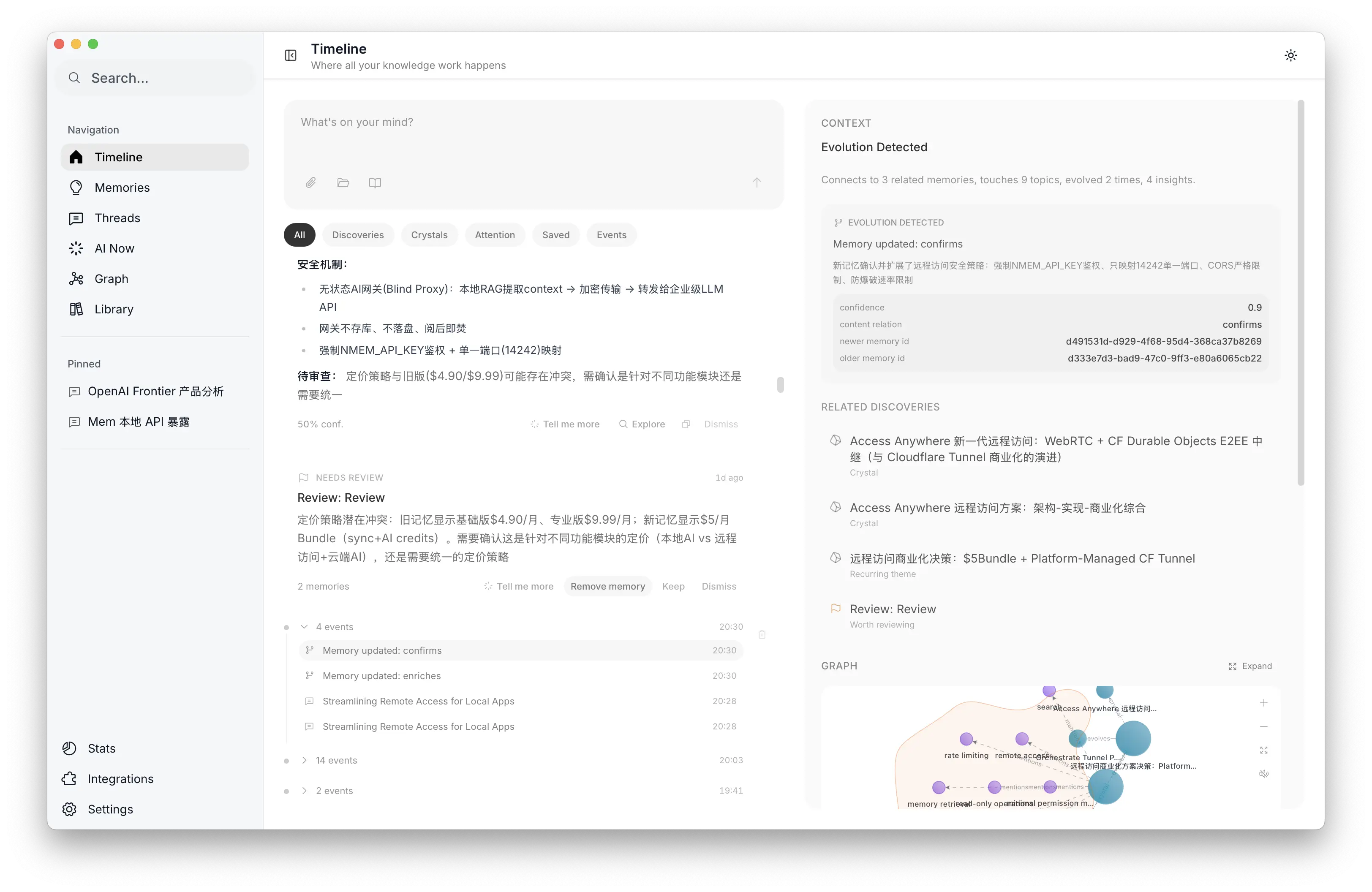 Timeline 中的演进检测与版本历史中的人工裁决
Timeline 中的演进检测与版本历史中的人工裁决
5. 遗忘:遗忘是 feature
大部分记忆系统忽略这一点。没有遗忘的记忆系统是垃圾场。
我们研究了两个框架:
- ACT-R(John Anderson, Carnegie Mellon):几十年的工作,研究人脑如何激活和遗忘记忆
- FSRS(叶峻峣):计算最佳复习时机,现在是 Anki 的默认算法
两个都很好,但解决的问题不同。FSRS 优化的是「我还记不记得这个」,需要用户显式评分 1 到 5。我们的问题是「什么值得此刻被关注」,是被动检索,没有反馈回路。
所以我们拆成两个独立的分数:
衰减随时间下降。指数衰减加对数频次修正。记忆自然淡去。
置信度只升不降。每一次搜索命中、每一次点击、每一条 EVOLVES 关系、每一次被 Crystal 引用,都在积累证据。confidence = max(new_value, old_value),永远不会减少。
重要性保底。 关键记忆(decision、核心 insight)有一个最低分数。即使几个月没碰过,也不会沉到搜不到。
代替显式评分,我们用 6 种隐式行为信号:搜索命中、结果展示、点击打开、阅读停留时长、EVOLVES 关联、被 Crystal 引用。EVOLVES 权重最高,因为知识图谱验证是我们拥有的最强置信度信号。
归档要求四个条件全部满足:衰减极低、零交互、超过 90 天、仍为活跃状态。系统宁可多留,不轻易删。
「没有遗忘的记忆系统是垃圾场。」
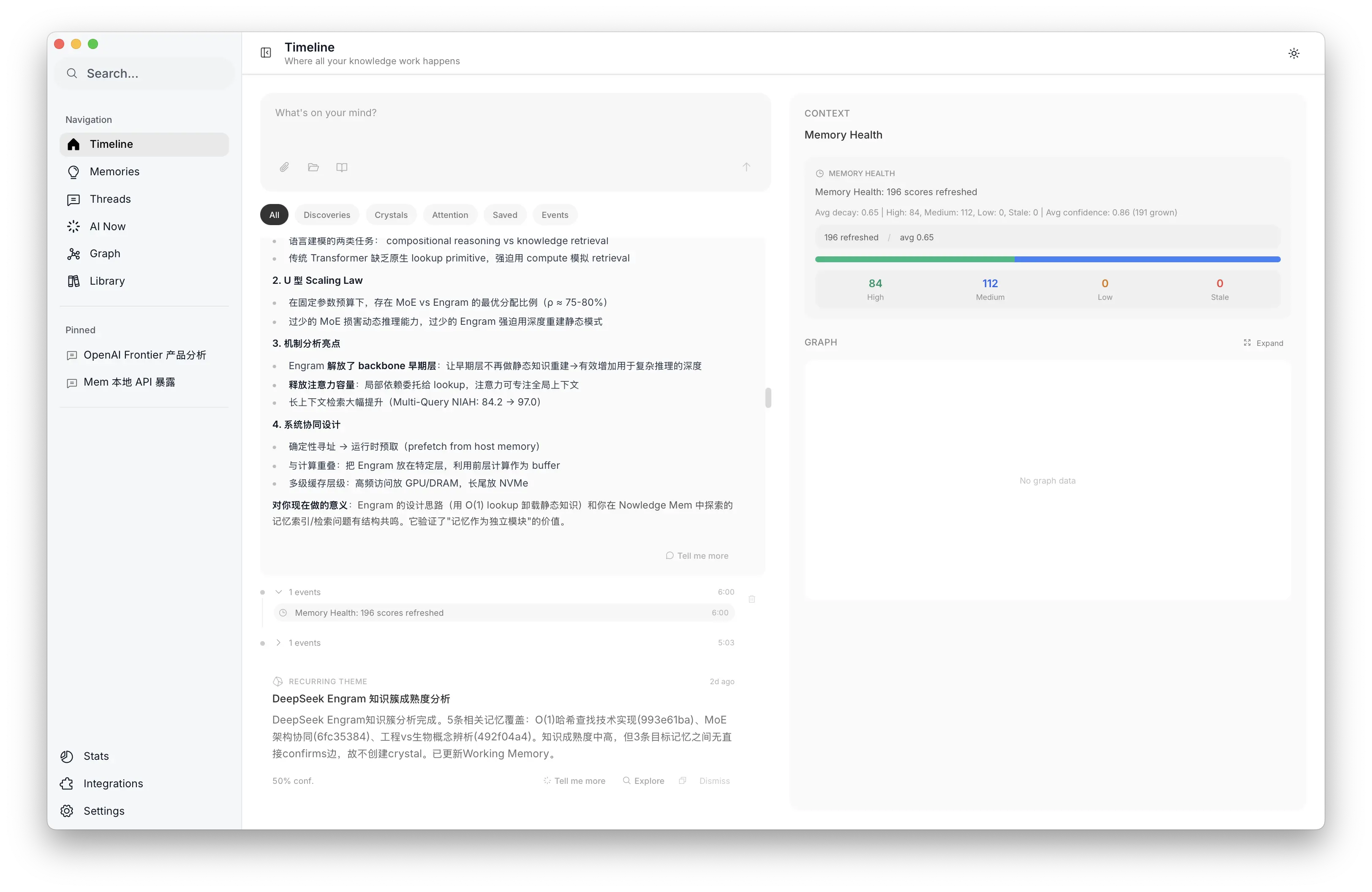 Memory Health 面板:衰减分布与置信度趋势
Memory Health 面板:衰减分布与置信度趋势
这些怎么组合到一起
超图
知识在系统里有三种形态(Trace、Unit、Crystal),组织在一个有 7 种节点、11 种边的图谱里。
图谱围绕渐进式揭露设计。Agent 不会一次加载全部。从轻量的语义搜索开始。需要更多上下文?查实体关系。需要历史?走版本链。需要全局视角?看社区聚类和 Crystal 洞察。
每一层有对应的原语工具。知识图谱不是用来看的,是用来 progressively traverse 的,每一次遍历都是一次推理。
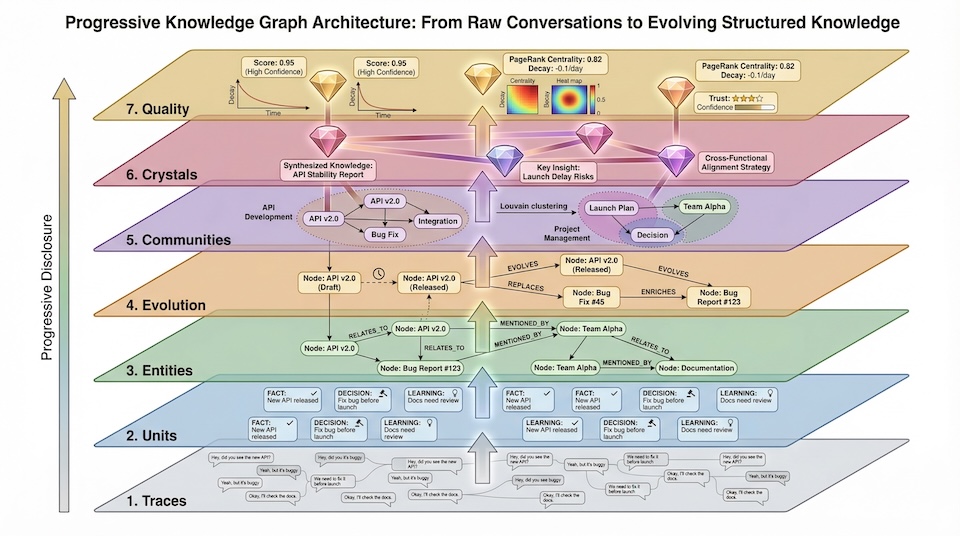 渐进式知识图谱:从 Trace 到 Quality 层
渐进式知识图谱:从 Trace 到 Quality 层
后台智能
EVOLVES 检测、实体提取、Crystal 形成、Working Memory 筛选。上面提到的所有自动行为,运行在 13 项后台任务中,分两类执行模型:
定时任务(cron)。 5 AM 晨间简报 → 归档昨日 WM → 生成今天的。6 AM 衰减刷新(纯计算,不调 LLM)。每周洞察检测、Crystal 巡检、低活跃记忆 compaction。每两周 Louvain 社区发现 + AI 摘要。
事件驱动(级联触发)。 一条新记忆进来,三条管线同时启动。EVOLVES 检测(30s debounce)、KG 实体提取(30s)、WM 增量刷新(300s)。如果 EVOLVES 发现 3+ 条关联记忆,自动触发 Crystal 评估。这是级联,不是调度。
任何任务启动前,context injection 预计算 Agent 需要的东西:48 小时活跃摘要、图谱统计、昨日 WM。硬上限 ~25K tokens。Agent 不做 discovery,每个 token 花在决策上。
四层护栏控制成本和噪音:
- Debounce:30s/300s 合并突发事件
- Rate limit:15 tasks/h,超额排队不丢弃
- Token budget:per-task + per-hour + per-day 三层
- Quality gate:代码级。空简报直接吞掉,连事件都不产生
掌控感
没有掌控感的记忆系统就是个数据库。掌控感体现在几件事上:
- 可见。 图谱可视化、版本历史、社区聚类。
- 可操作。 编辑、删除、矛盾裁决、标签管理。
- AI 原生。 自然语言调度任何知识任务。「帮我整理上周的 decision。」「分析我在 React 领域的知识分布。」
- 数据主权。 本地存储、非二进制格式、随时可导出、丰富的 API(包括图谱可视化 API)。
- 无处不在。 桌面端、iOS、Android、TUI、CLI、MCP。
看不到就不信任,不信任就不用,不用和没有一样。
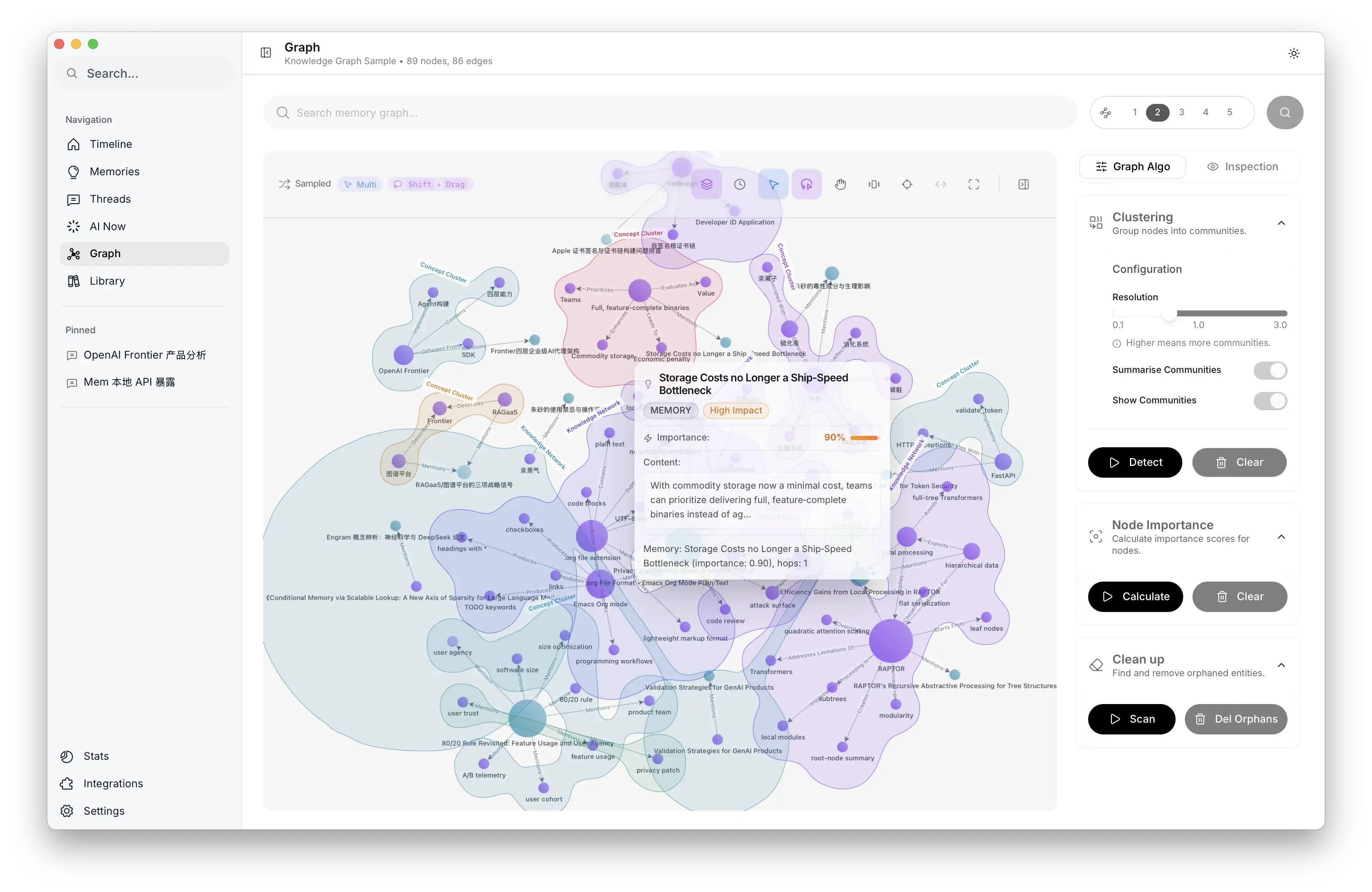 图谱探索:社区聚类、节点重要性、全局分析
图谱探索:社区聚类、节点重要性、全局分析
连接层
做记忆系统是一回事。把它接到用户实际在用的每一个工具上,更难。
8 个原生插件:Claude Code、Cursor、Codex、Gemini CLI、OpenClaw、Bub、Alma、Droid。浏览器扩展自动同步 14 个 AI 平台的对话。原生连接 Obsidian、Apple Notes、Notion。桌面端、iOS、Android、CLI、Raycast、MCP。
每个插件有完整的生命周期,不是简单调一下 MCP。启动时注入 Working Memory,过程中捕获知识,结束时蒸馏入图谱。
每个工具有自己的 session 模型。Claude Code 是长对话,Cursor 是短任务,浏览器标签页是零散片段。连接层让知识在所有工具之间流动。
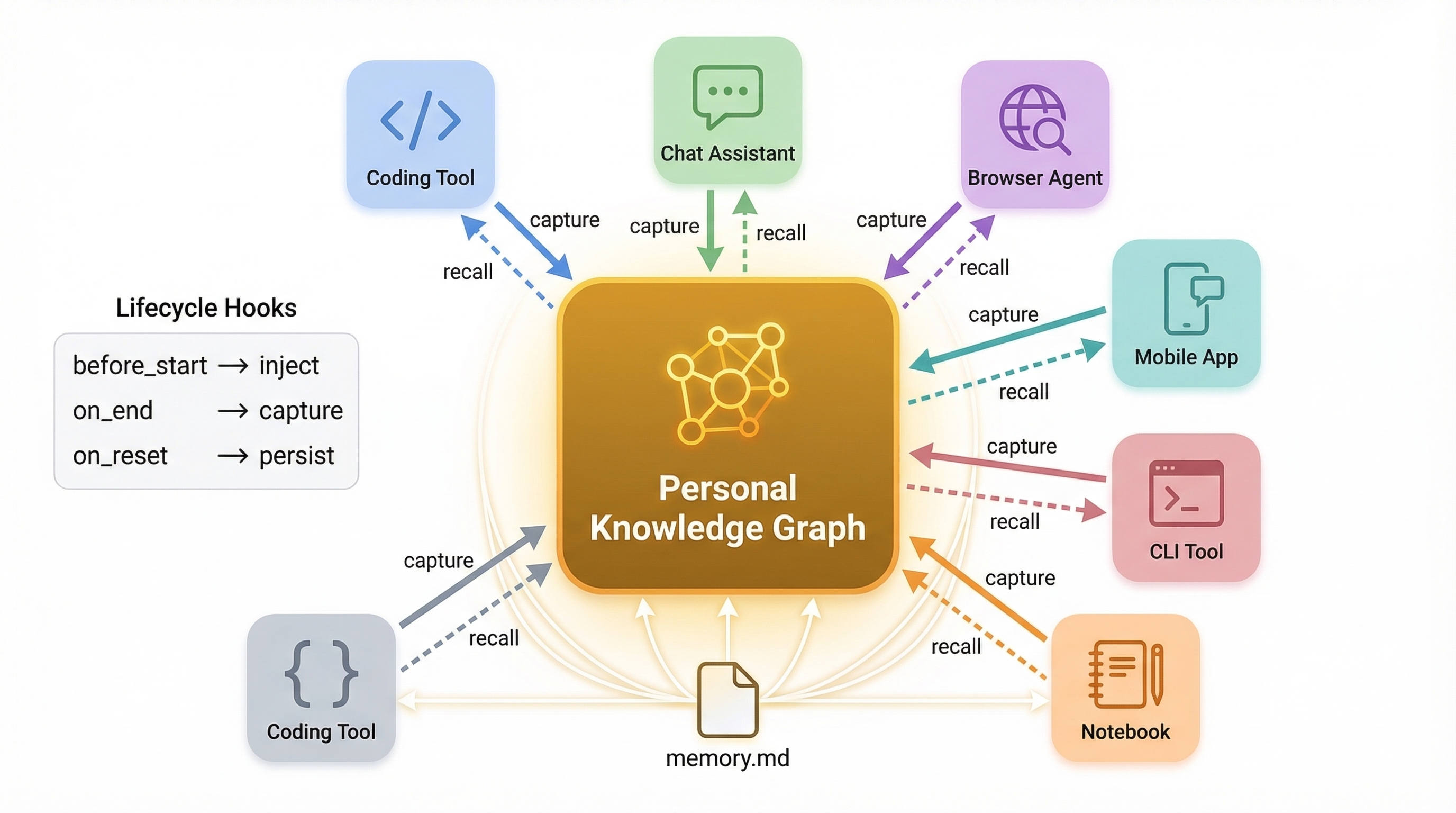 跨 Agent 连接层:个人知识图谱在中心
跨 Agent 连接层:个人知识图谱在中心
做下来之后的四个判断
A. 记忆变成了标配。 每个 AI Native 产品都在做自己的记忆。ChatGPT、Claude、Cursor、Gemini,各不相同,互不兼容。这不会自己收敛。需要一个聚合层,像 1Password 管密码那样管知识。
B. 记忆比工具活得久。 2023 年的 Agent 框架还有几个活着?Langchain、AutoGPT、BabyAGI。工具会换代,记忆不能跟着消失。本地存储、开放格式、随时可导出。用户掌控不了自己的数据,就不会信任你。
C. 记忆系统的瓶颈在智能,不在存储。 五个挑战归根到底都是这一条。蒸馏是分类,检索是排序,遗忘是注意力分配。记忆系统的核心不是数据库,是一条决策链,每一步都需要 Agent 级别的判断力。
D. 记忆的终局是可执行的经验。 记忆 → 结晶 → 技能。CLAUDE.md 和 SKILLS.md 今天是手写的判断力形式化。抽象是对的,但是手工活。SkillCraft(Chen et al., 2026)证明 tool composition 可以缓存为 skill,token 降 80%。Yansu(Isoform)走得更远:结晶知识变成可执行应用。下一步是让系统从记忆中自动生成。
接下来
图上学习。 图谱目前做存储、遍历和图算法。下一步是 GNN-based 的预测性推理,在端侧运行。哪些记忆即将过时?哪些 decision 之间有冲突?哪些跨领域的隐性连接还没被发现?从被动问答到主动预警。
结晶 → 技能自动化。 Crystal pipeline 已经产出了 Agent skill 的原料。SkillCraft 和 Yansu 指明了方向。下一步是谨慎地自动化这条链路:记忆 → 结晶洞察 → 经过验证的可执行技能。
自适应记忆架构。 MemEvolve 证明记忆架构本身可以被进化。不同用户和工作流需要不同的记忆策略、衰减参数、检索偏好。我们的方向是让系统学习每个用户的记忆风格,但有一个硬约束:用户必须能理解和信任系统的判断。Personalized,不是 fully autonomous。
基于 2026 年 3 月 21 日在 vLLM 北京 Meetup 和 KCD(Kubernetes Community Days)的分享。视频录像即将放出,关注 @NowledgeMem 获取更新。
Slides: https://siwei.io/talks/memory-2026/